问题背景
接收到告警短信,web应用登陆无响应,请求api均为504
影响范围
平台无法正常使用
排查过程
一般情况下,cpp应用占用cpu较高的原因大部分分为以下两个情况:
- 应用属于计算密集型应用
使用大量CPU会导致平均负载升高,此时system load和cpu使用数率值上是一致的 - 应用中出现了
IO密集型应用
等待I/O也会导致平均负载升高,但CPU使用率不一定很高,所以system load和cpu使用率并不会一致
查询该机器的系统负载(system load)
1.系统负载:
是指系统cpu繁忙程度的度量指标,即有多少个进程在等待被cpu调度,就是进程等待cpu的队列长度2.平均负载:
是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用CPU的进程,还包括等待CPU和等待I/O的进程,实际上是系统的平均活跃进程数统计3.uptime详解
1
2
3
4
5
6
7
8// 观察uptime刷新,w命令/top命令皆可查询到系统的平均负载
watch -D uptime
// 得到结果
11:10:17 up 628 days, 14:06, 2 users, load average: 0.05, 3.53, 6.59
// 11:10:17是指当前系统时间
// up 628 days, 14:06 是指机器运行时间
// 2 users:是指当前登陆有2个用户
// load average: 0.05, 3.53, 6.59:是指当前1分钟/5分钟/15分钟的平均负载指假设平均负载是
2,当前cpu数是2cores则说明cpu被100%使用,如果是4cores则说明cpu利用率是50%,如果是1cores,则说明有一半的进程都竞争得不到cpu3.如何查看机器的核心(core)呢
1
cat /proc/cpuinfo | grep cores | wc -l
- 4.如何查看机器是否开启超线程呢?比如我们的机器2颗物理cpu,在每颗物理cpu上又做了6颗逻辑CPU,之后在每颗逻辑CPU上又实现了超线程后,假如此时你在系统中使用cat /proc/cpuinfo |grep ‘processor’|wc –l返回24颗,如果load值(15分钟的返回值作为参考依据)长期在24以上,说明系统已经很繁忙了。
1
2// 如何得到的值和grep cores后得到的核心数一致,则说明未开启
cat /proc/cpuinfo | grep processor | wc -l
具体分析系统瓶颈
结合平均负载分析,假如我们当前已经知道load很高,但是仍然无法判断是cpu占用率高,还是系统I/O繁忙,又或者是内存不足导致的?
- 1、procs列
r 列表示运行和等待cpu时间片的进程数,如果长期大于cpu核心数,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
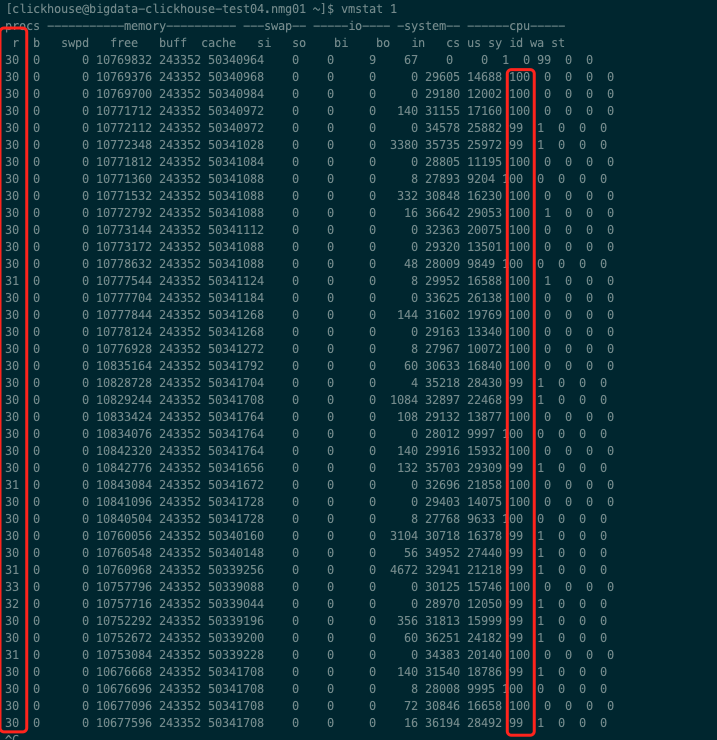
2、system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs 列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。3、memory列
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。4、swap列
si 由内存进入内存交换区数量。
so 由内存交换区进入内存数量。
si、so的值长期为0,系统性能还是正常5、IO列
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。6、cpu列
cs 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足
id 列显示了cpu处在空闲状态的时间百分比
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
通过以上分析,可以知道当前机器的瓶颈是cpu负载过高,那么如何知道哪个进程占用cpu资源呢?
查询该机器cpu占用最高的进程
1 | // 每5秒统计一次 |
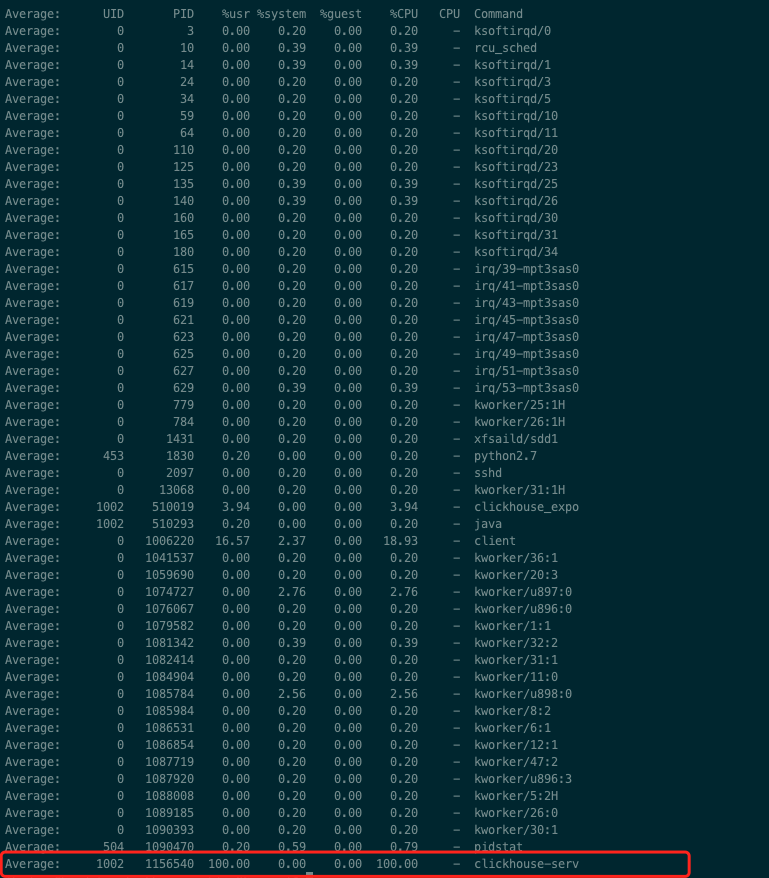
也可以使用
top命令查询到cpu占用最高的进程
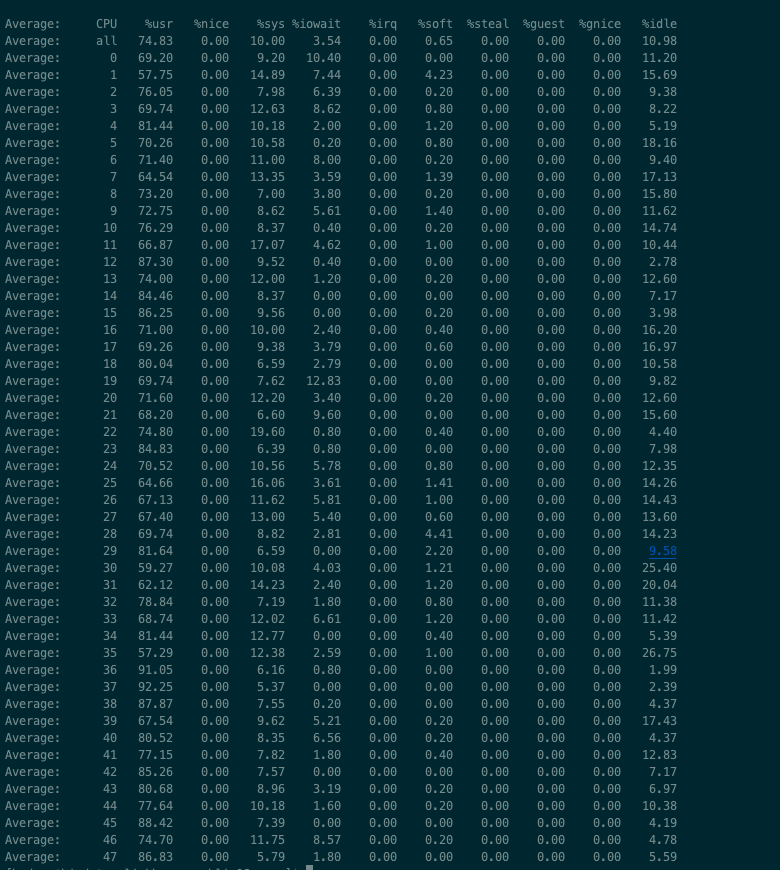
查询该机器的cpu使用情况
1 | // 每5秒刷新一次查看所有cpu的统计情况 |
查看到进程ID后,可以通过ps aux | grep pid查看进程的详情
1 | ps aux | grep pid |

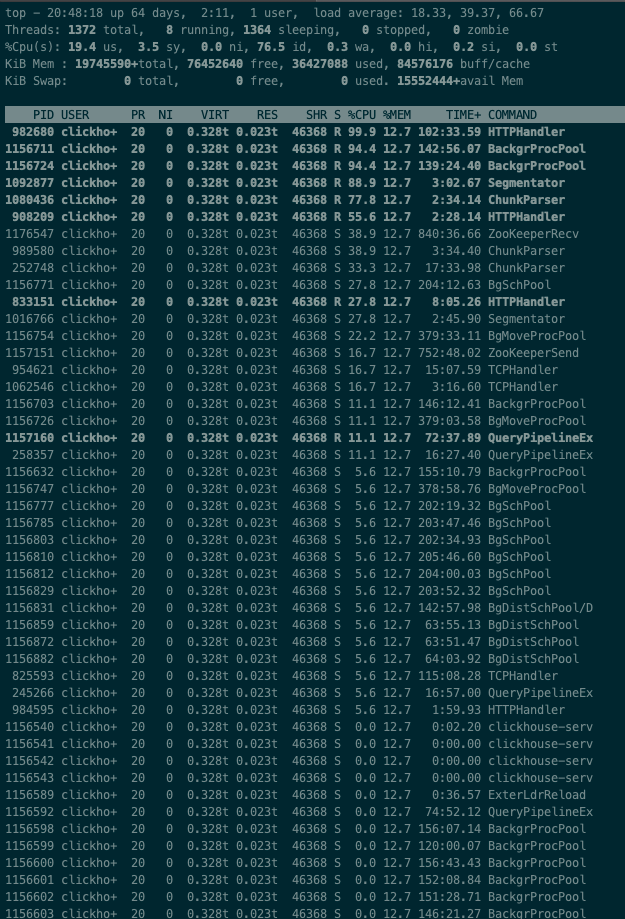
定位到最耗cpu的进程后,使用top -Hp pid命令查看线程列表,并找到占用cpu最高的线程
1 | // `tid`表示线程`ID`,`time`表示线程已经运行的时间 |
将需要的线程ID转换为16进制格式,可以使用printf "%x\n" tid命令
1 | printf "%x\n" tid |