背景介绍
- 首先解释下为什么要写入分布式表,而不是
MergeTree表
分布式表链接,分布式表引擎不会存储任务数据,但是允许分布式查询可以路由到多台机器,读取都是并行的,每一个读操作,如果有配置的话,远程机器上的表索引都会被使用到,所以我们知道分布式表是不存储数据的,只是数据的搬运工而已,我们正常做法应该是直接写入数据到MergeTree引擎表,然后通过分布式做路由分发查询而已。那么问题来了,什么场景要写入到分布式表呢?
因为分布式表建表语句支持指定分片索引sharding_key,这个sharding_key可以把通过分布式表写入的数据转发到同一个shard,那么在同一个shard里的数据才能满足排序主键和去重。1
2
3
4
5
6
7CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...] - 可以使用
xxHash32函数来对要去重的字段进行哈希计算后路由到同一个分片上1
ENGINE = Distributed('cluster', 'database', 'table_local', xxHash32(logid))
system.metrics
介绍
地址,该表包含了被直接算计的指标,或者当前值,举例就是同时查询的进程数,或者当前副本延迟时间,这个表一直被实时更新。
该表包含3个元素,如下- metric (String) — 指标名.
- value (Int64) — 指标值.
- description (String) — 指标描述.
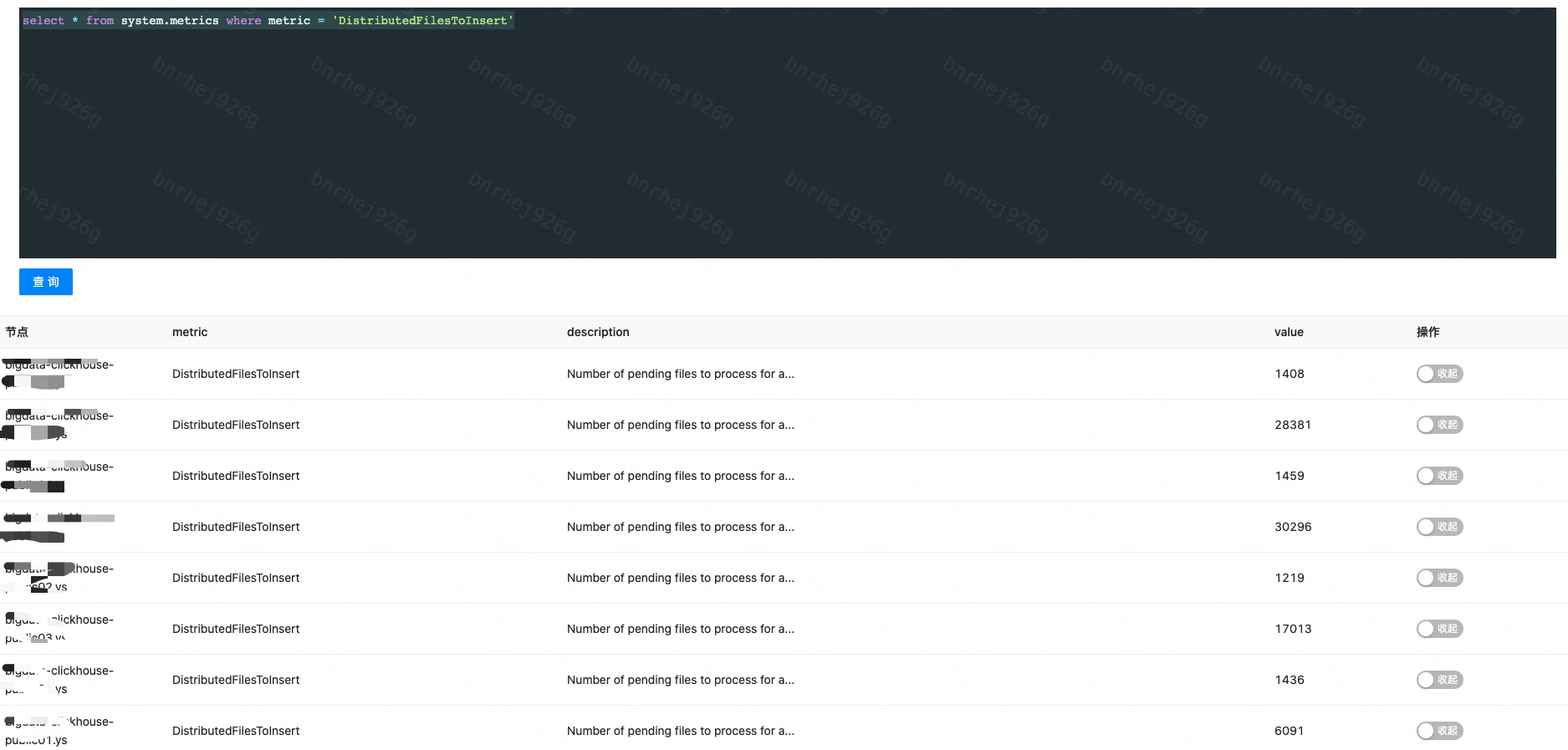
找出当前每个节点分布式文件写入的总数,找出最高的那个节点
1
select * from system.metrics where metric = 'DistributedFilesToInsert'
system.distribution_queue
- 介绍
地址,该表包含了关于本地文件等待传递到shard的队列信息,这些本地文件包含的用异步方式通过写入分布式表创建的新part文件。
该表包含字段如下:
database (String) — 数据库名称.
table (String) — 表名称.
data_path (String) — 本地文件的路径.
is_blocked (UInt8) — 标示位,是否传递文件到服务器被锁住.
error_count (UInt64) — 错误数.
data_files (UInt64) — 一个目录下文件个数.
data_compressed_bytes (UInt64) — 单位字节,被压缩的数据大小.
broken_data_files (UInt64) — 由于错误而标示损坏的文件数.
broken_data_compressed_bytes (UInt64) — 单位字节,所损文件的压缩字节大小.
last_exception (String) — 上次发生错误的内容.
- 去最高的那个节点查找正在写入的队列
1
select * from system.distribution_queue where data_files > 0
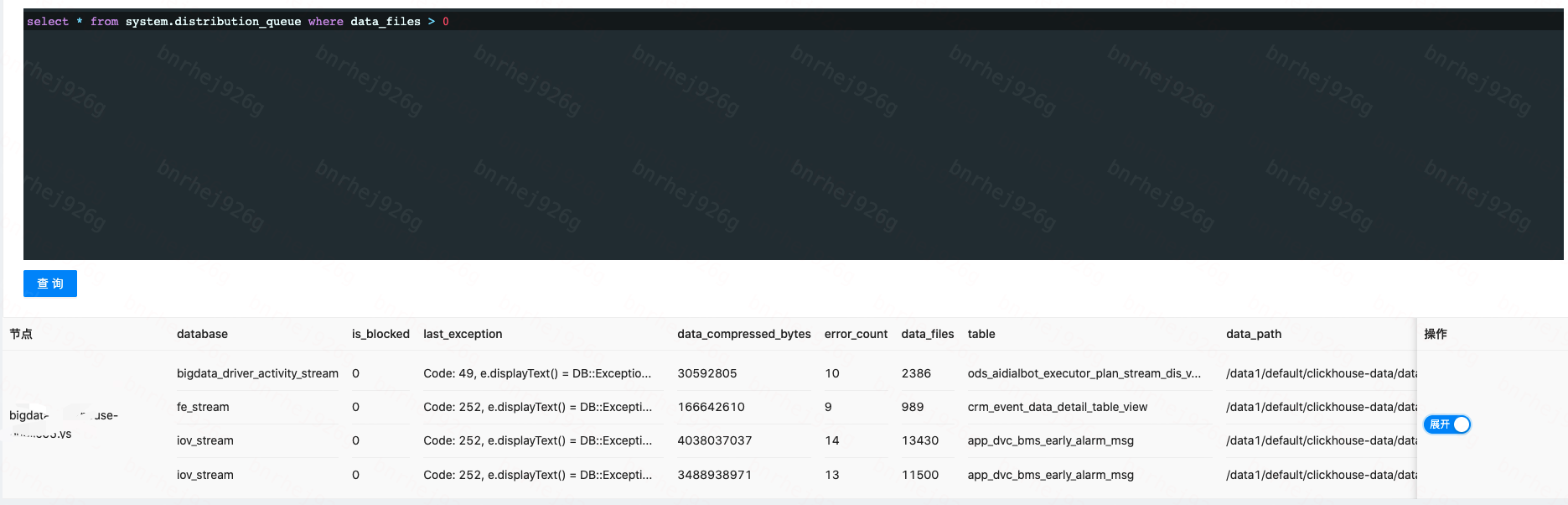
通过
data_files可以看到当前在等待写入的文件数,通过data_compressed_bytes可以看到当前等待写入的总文件大小,通过error_count可以看到错误次数,通过last_exception可以看到上次发生错误的内容
若是clickhosue19版本,则使用以下命令查询
- 查出分布式表存储的路径配置
1
2
3cd config.d
cat storage.xml
<path>/data1/default/clickhouse-data</path>如果不是这样的配置,直接查询
storage_configuration的配置 进入分布式表的存储目录,计算出每个库表的总文件数
1
2
3
4
5
6
7cd /data1/default/clickhouse-data/data
# find -type f 表示查找出所有类型是文件的格式
# awk -F ',' '{print $1}' 表示按照,切割后取第一个
# uniq -c 表示聚合后去重
# sort -h -r 表示逆序排序
# awk -F '/default' '{print $1}' 表示按/default切割后取第一条
find -type f | awk -F ',' '{print $1}' | uniq -c | sort -h -r | awk -F '/default' '{print $1}'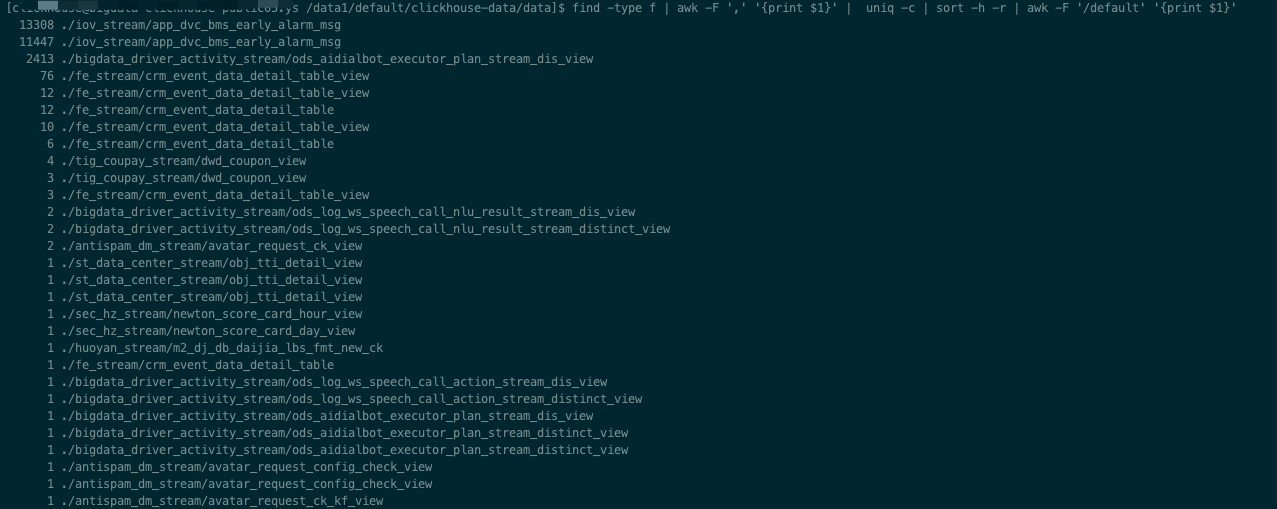
文件数目最多的就是写入积压的
根据flush命令获取到写入错误的原因
1
SYSTEM FLUSH DISTRIBUTED db.tb
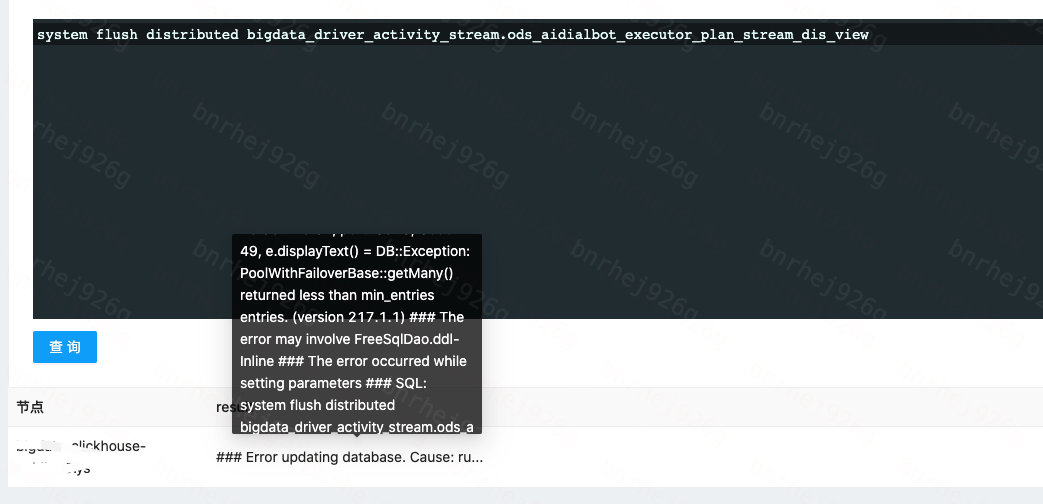
根据错误能直接解决就直接去解决,无法解决的话看下面
解决分布式表写入积压
- 删除分布式表
则意味着这个分布式表的所有写入任务都会自动清理,谨慎操作,别把底表删了
1
drop table if exists db.tb
- 清空分布式表数据
这个方式只是清除掉积压的数据,不用删表,用户通过分布式表来查询时不会报表不存在,但是如果数据量非常大就不要用truncate方式了,因为会导致整个表被锁非常久,应该用
alter table xx drop partititon xx方式,一个一个分区删。1
truncate table db.tb