问题描述
用户反馈api请求时快时慢,慢的时候网页打开很久都没有结果,直到超时给出500错误
排查过程
初步怀疑
当前程序分布式部署在多个节点上,通过vip进行负载均衡,所以对于直接将反馈慢的页面打开的请求通过curl方式登陆生产环境所有节点,进行轮训一遍,发现其中02节点需要等待很久,其他节点均正常,所以问题应该出在02节点,
注意:这个定位过程当然也可以使用监控图就一目了然了。推荐使用grafana prometheus spring boot dashboard在google搜寻下相关配置就可以了。
查询该节点负载
1 | # 得到进程的pid |
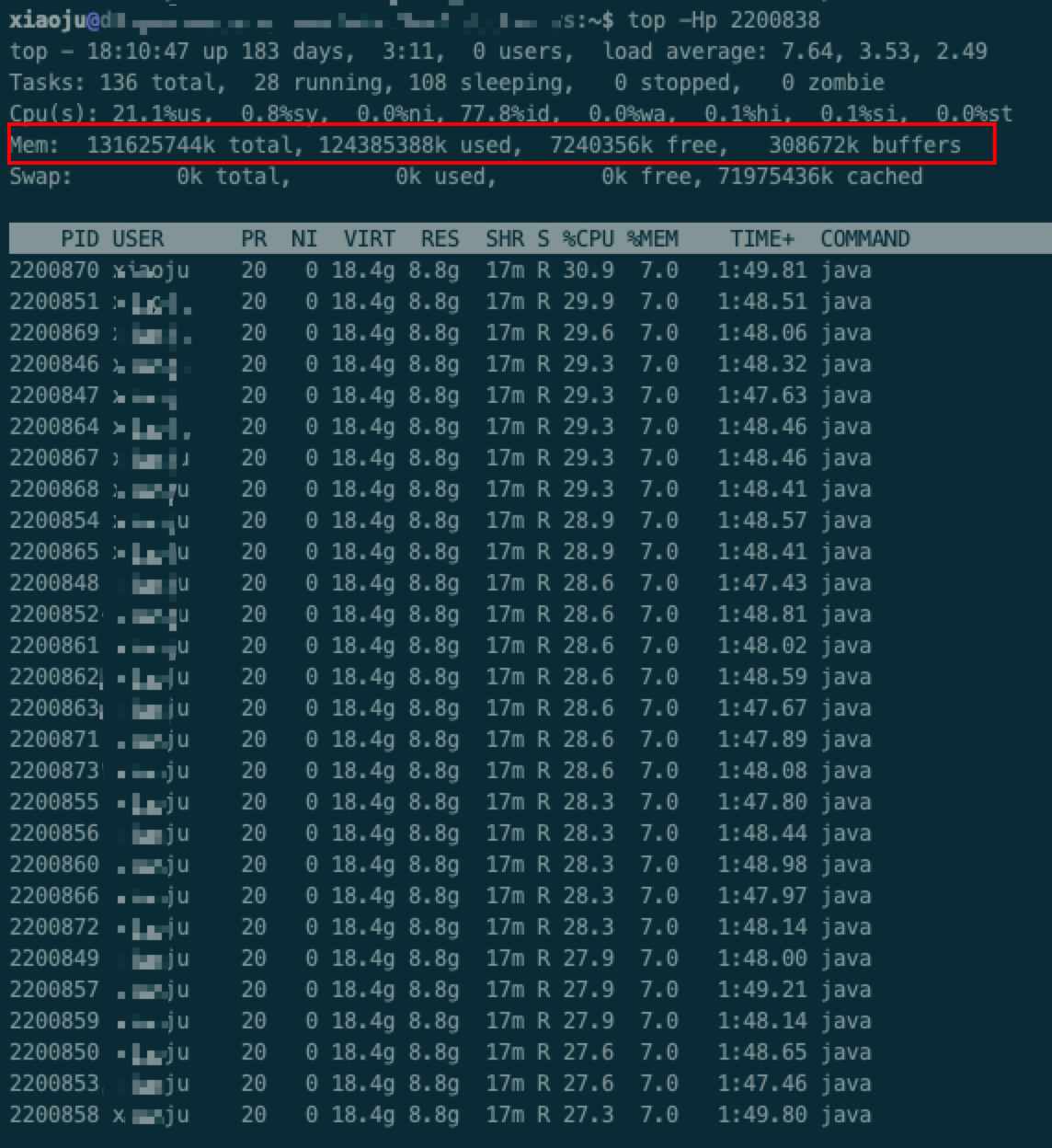
通过top命令发现该节点memory使用了接近
90%,怀疑出现内存泄露
查询该节点内存使用情况
1 | jstat -gcutil pid 1000 |
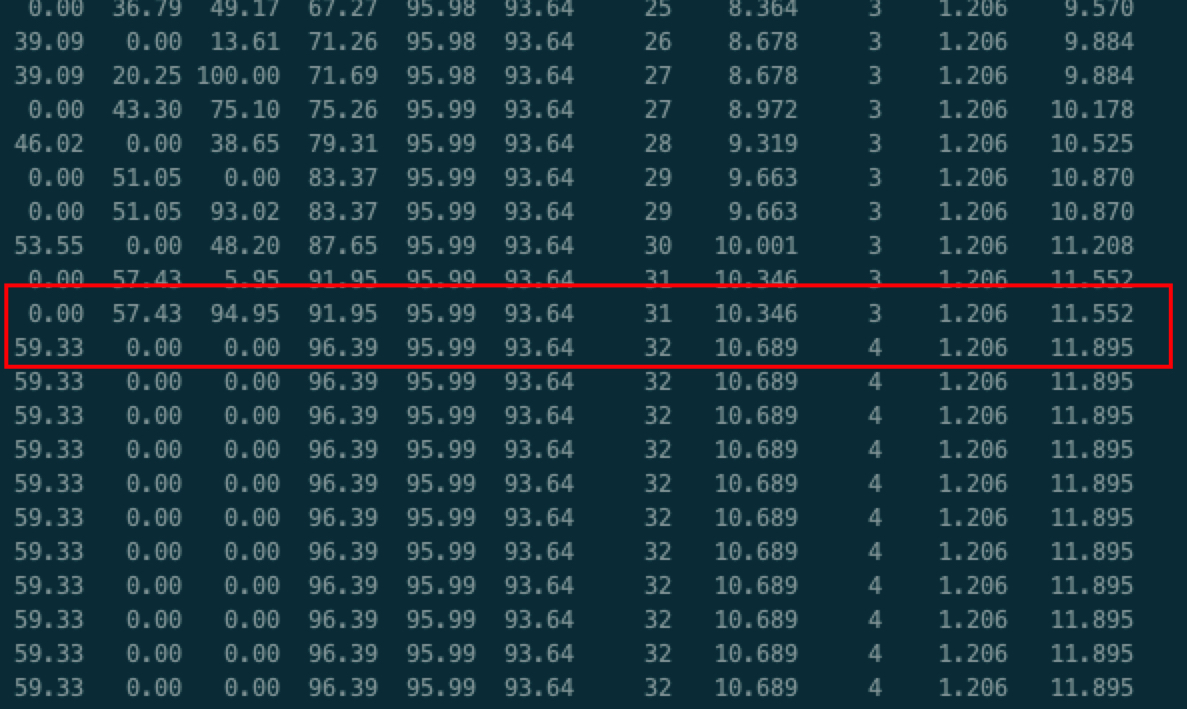
如我所料,几乎不到
1s就开始做一次fgc,所以服务才越来越慢响应
内存分析
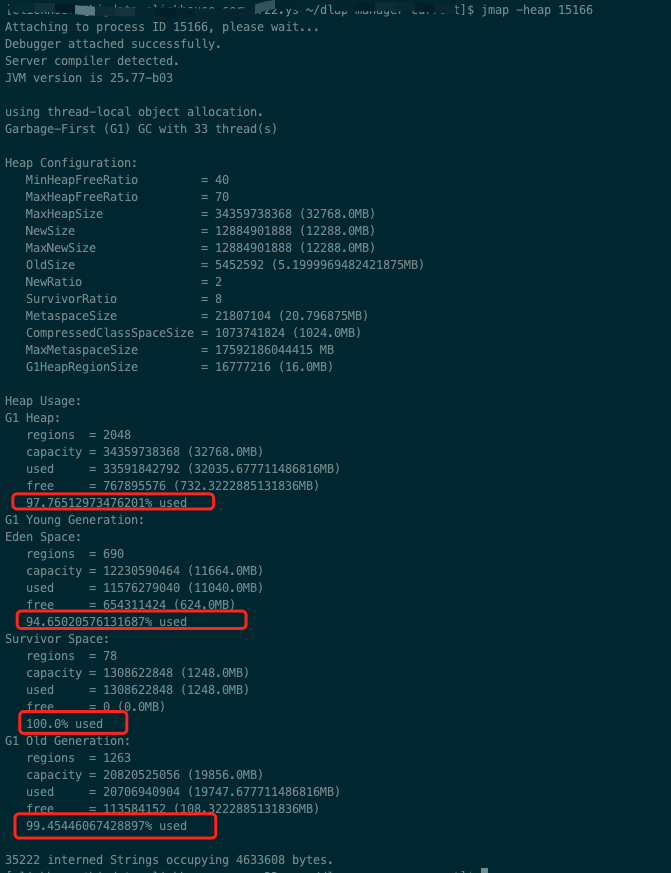
使用jmap分析内存概要
1 | jmap -heap pid | head -n20 |
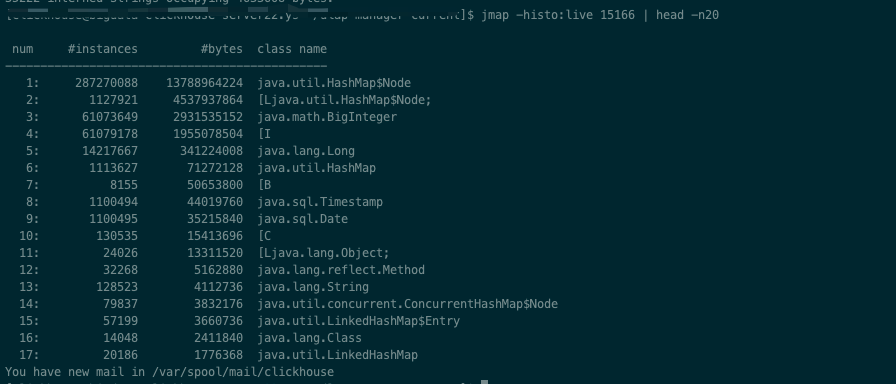
使用jmap打印堆内存的对象,带上live,则只统计活着的对象
1 | jmap -histo pid | head -n20 |
打印进程的内存使用情况
1 | jmap -dump:format=b,file=dumpFileName pid |
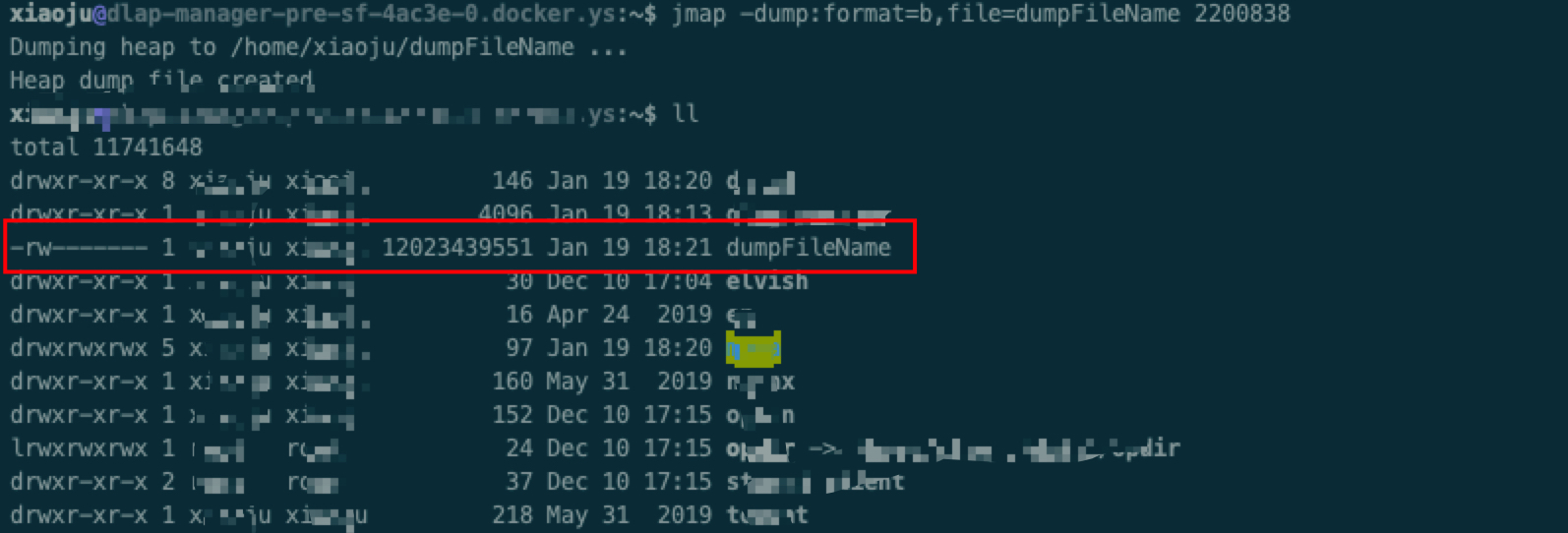
dump出来了
12G的文件,通过scp工具转存到本地
jprofiler分析堆内存
- 1、把dumpFileName文件转存为.hprof格式后直接双击打开,按照instance count逆序排列
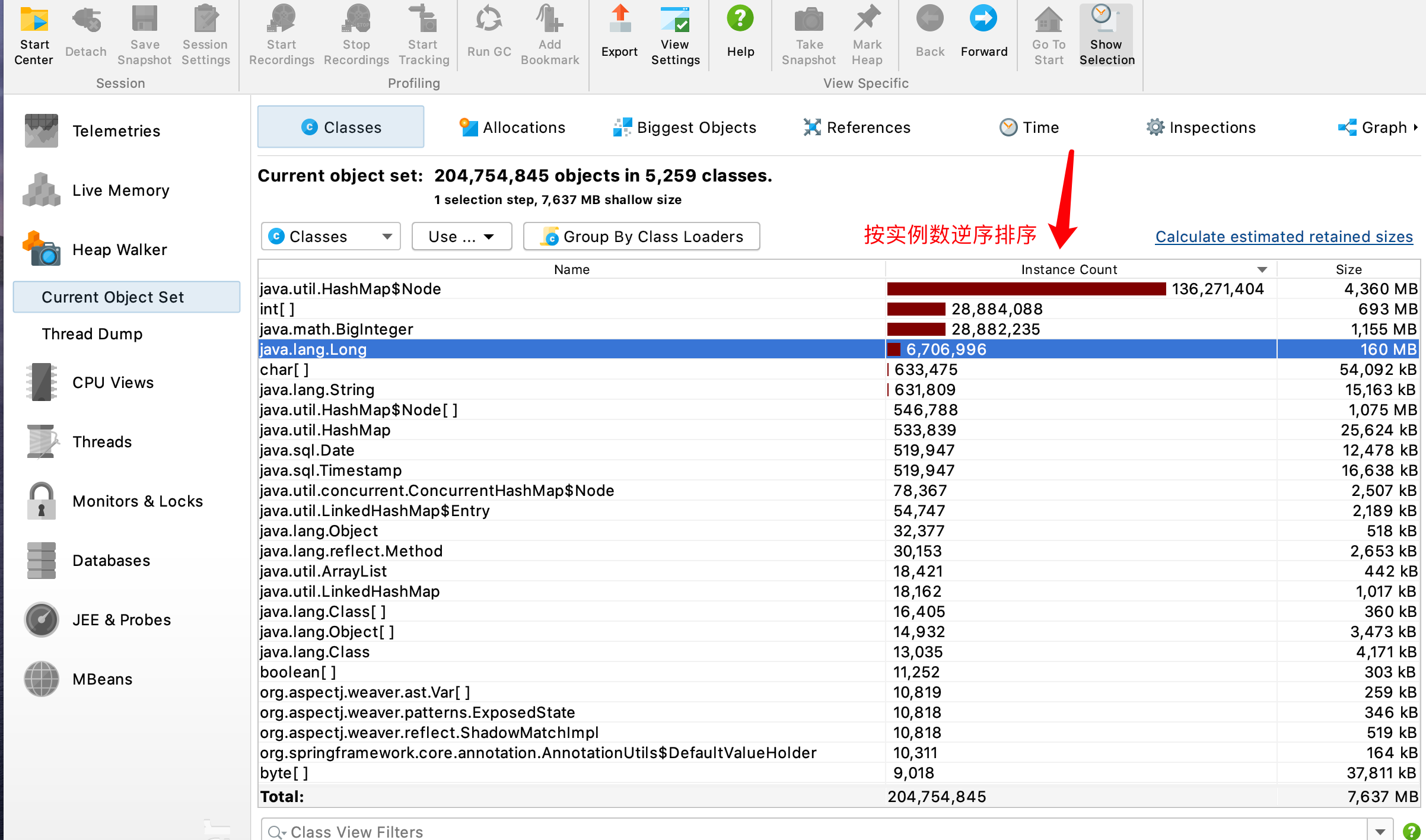
- 2、会发现有hashmap类型占了最大头,但是这个类型,双击它,选择
merged incoming reference,查看合并后的来源引用统计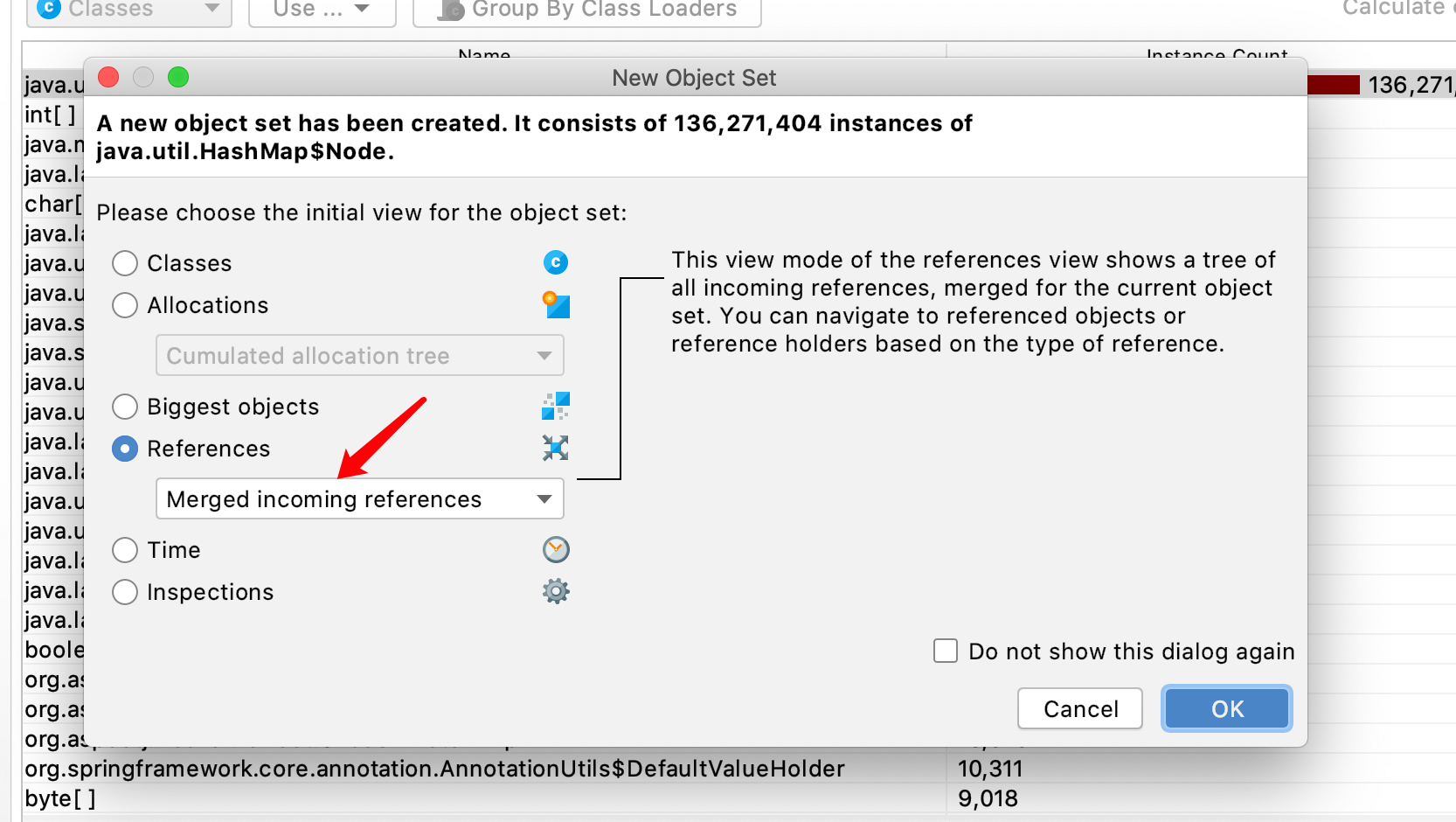
- 3、还是选最大头的文件数一直拆到最里层,找出来源引用是
org.apache.ibatis.executor.result.DefaultResultHandler这个类,基本能定位到问题根源了,是我们连接clickhouse客户端去查询结果时,未对结果集做限制,导致了一个很大的结果集返回到内存中。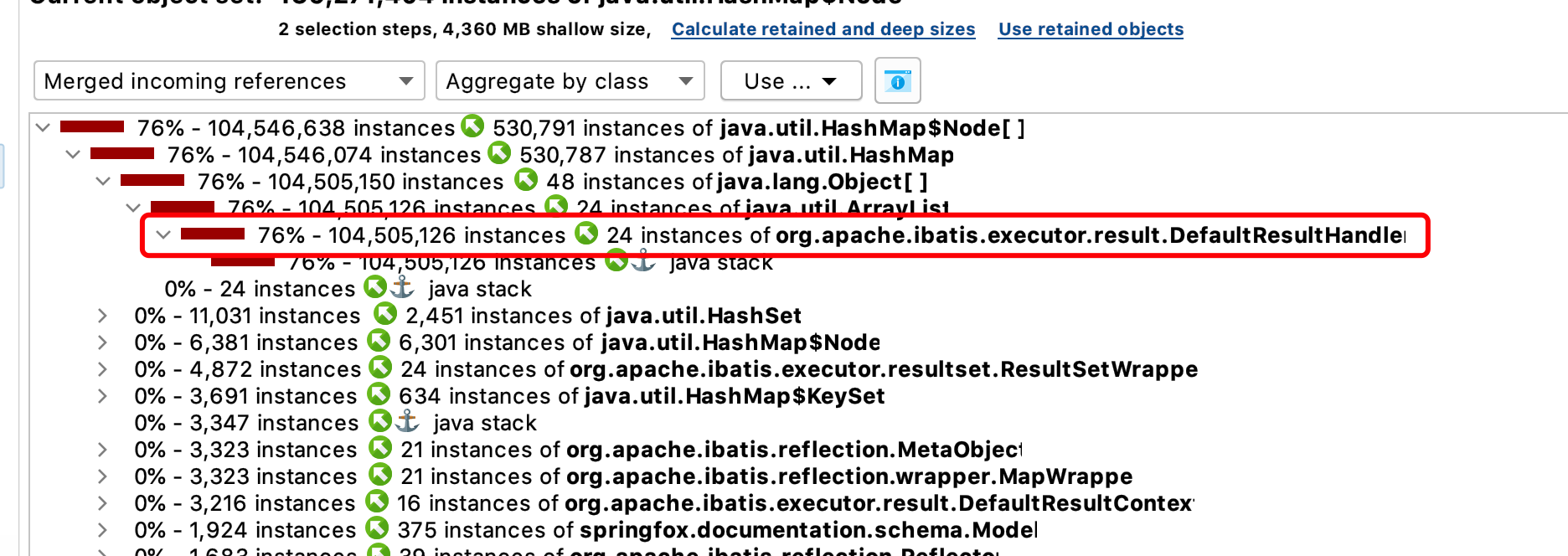
解决问题
当然是对结果集做限制,检测用户输入的sql,是否包含limit条数限制,若未限制,则对sql进行改写,增加500条数限制
GC的运行原理
GC(garbage collection):垃圾回收,主要是指YGC和FGCYGC(minor garbage collection):新生代垃圾回收FGC(major garbage collection):老年代垃圾回收
堆内存结构
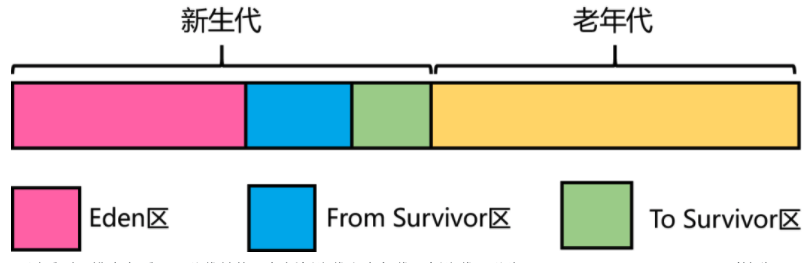
堆内存采用了分代结构,包括新生代和老年代,新生代分为:eden区、from survivor区(简称s0)、to survivor区(简称s1),三者默认比例上8:1:1,另外新生代和老年代的比例则是1:2。
堆内存之所以采用分代结构,是因为绝大多数对象都是短生命周期的,这样设计可以把不同的生命周期的对象放在不同的区域中,然后针对新生代和老年代采用不同的垃圾回收算法,从而使得GC效率最高。
YGC是什么时候触发的?
大多数情况下,对象直接在年轻代中的Eden区进行分配,如果Eden区域没有足够的空间,那么就会触发YGC(Minor GC),YGC处理的区域只有新生代。因为大部分对象在短时间内都是可收回掉的,因此YGC后只有极少数的对象能存活下来,而被移动到S0区(采用的是复制算法)。
当触发下一次YGC时,会将Eden区和S0区的存活对象移动到S1区,同时清空Eden区和S0区。当再次触发YGC时,这时候处理的区域就变成了Eden区和S1区(即S0和S1进行角色交换)。每经过一次YGC,存活对象的年龄就会加1。
FGC是什么时候触发的?
1、
YGC时,To Survivor区不足以存放存活的对象,对象会直接进入到老年代。经过多次YGC后,如果存活对象的年龄达到了设定阈值,则会晋升到老年代中。动态年龄判定规则,To Survivor区中相同年龄的对象,如果其大小之和占到了To Survivor区一半以上的空间,那么大于此年龄的对象会直接进入老年代,而不需要达到默认的分代年龄。大对象:由-XX:PretenureSizeThreshold启动参数控制,若对象大小大于此值,就会绕过新生代, 直接在老年代中分配。当晋升到老年代的对象大于了老年代的剩余空间时,就会触发FGC(Major GC),FGC处理的区域同时包括新生代和老年代。老年代的内存使用率达到了一定阈值(可通过参数调整),直接触发FGC。2、空间分配担保:在
YGC之前,会先检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。如果小于,说明YGC是不安全的,则会查看参数HandlePromotionFailure是否被设置成了允许担保失败,如果不允许则直接触发Full GC;如果允许,那么会进一步检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果小于也会触发Full GC。3、
Metaspace(元空间)在空间不足时会进行扩容,当扩容到了-XX:MetaspaceSize参数的指定值时,也会触发FGC。4、
System.gc() 或者Runtime.gc() 被显式调用时,触发FGC。
GC对程序会产生什么影响
不管是YGC还是FGC,都会造成一定程度上的程序卡顿(stop the world问题:GC线程开始工作,其他工作线程被挂起),即使采用ParNew、CMS、G1这些更先进的垃圾回收算法,也只是减少卡顿的时间,并不能完全消除卡顿
- FGC过于频繁:
FGC通常是比较慢的,少则几百号秒,多则几秒,正常情况下FGC每隔几个小时或者几天才会执行一次,对系统的影响是可接受的,所以一旦出现FGC频繁(比如几分钟/几十分钟出现一次)会导致工作线程频繁被停掉,让系统看起来就一直卡顿,使得程序的整体性能变差。 - YGC耗时过长:
一般来说YGC的总耗时指需要几十毫秒或上百毫秒,对于系统来说几乎无感知,所以如果YGC耗时达到1秒甚至几秒(快赶上FGC的耗时),那么卡顿就会加剧,加上YGC本身会比较频繁发生,就可能导致服务响应时间超时。 - FGC耗时过长:
FGC耗时增加,卡顿时间也会随之增加,尤其对于高并发服务,可能导致FGC期间比较多的超时问题,可用性降低,这种也需要关注 - YGC过于频繁:
即使YGC不会引起服务超时,但是YGC过于频繁也会降低服务的整体性能,对于高并发服务也是需要关注的。
其中,「FGC过于频繁」和「YGC耗时过长」,这两种情况属于比较典型的GC问题,大概率会对程序的服务质量产生影响。剩余两种情况的严重程度低一些,但是对于高并发或者高可用的程序也需要关注。
导致FGC的原因总结
- 大对象:系统一次性加载了过多数据到内存中(比如SQL查询未做分页),导致大对象进入了老年代。(即本文中的案例)
- 内存泄漏:频繁创建了大量对象,但是无法被回收(比如IO对象使用完后未调用close方法释放资源),先引发FGC,最后导致OOM.
- 程序频繁生成一些长生命周期的对象,当这些对象的存活年龄超过分代年龄时便会进入老年代,最后引发FGC.
- 程序BUG导致动态生成了很多新类,使得 Metaspace 不断被占用,先引发FGC,最后导致OOM.
- 代码中显式调用了gc方法,包括自己的代码甚至框架中的代码。
- JVM参数设置问题:包括总内存大小、新生代和老年代的大小、Eden区和S区的大小、元空间大小、垃圾回收算法等等。