分布式DDL执行链路
在介绍具体的分布式
DDL执行链路之前,先为大家梳理一下哪些操作是可以走分布式DDL执行链路的,大家也可以自己在源码中查看一下ASTQueryWithOnCluster的继承类有哪些: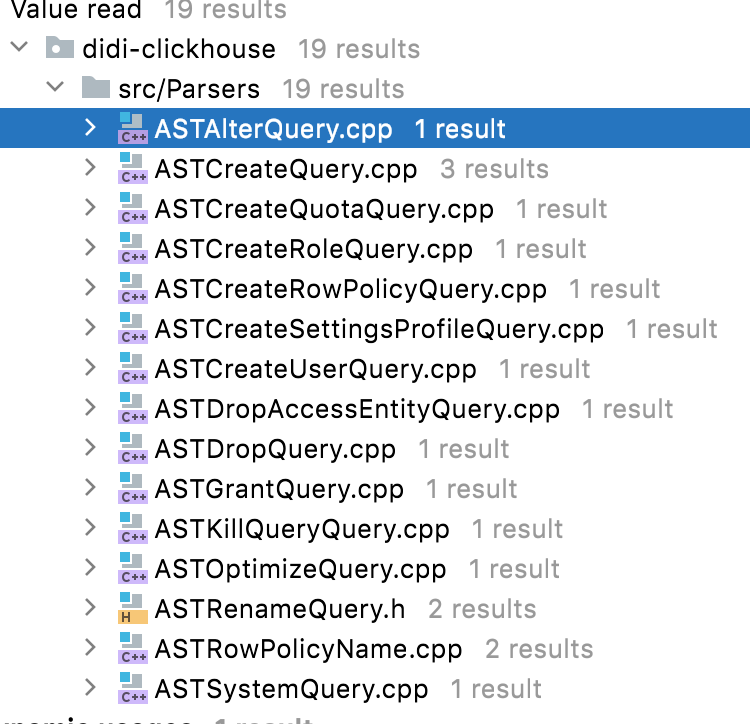
- ASTAlterQuery:
包括ATTACH_PARTITION、FETCH_PARTITION、FREEZE_PARTITION、FREEZE_ALL等操作(对表的数据分区粒度进行操作)。 - ASTCreateQuery:
包括常见的建库、建表、建视图,还有ClickHouse独有的Attach Table(可以从存储文件中直接加载一个之前卸载的数据表)。 - ASTCreateQuotaQuery:
包括对租户的配额操作语句,例如create quaota,或者alter quota语句 - ASTCreateRoleQuery:
包括对租户角色操作语句,例如create/alter/drop/set/set default/show create role语句,或者show roles - ASTCreateRowPolicyQuery
对表的查询做行级别的策略限制,例如create row policy或者alter row policy - ASTCreateSettingsProfileQuery
对角色或者租户的资源限制和约束,例如create settings profile或者alter settings profile - ASTCreateUserQuery
对租户的操作语句,例如create create user或者alter create user - ASTDropAccessEntityQuery
涉及到了clickhouse权限相关的所有删除语句,包括DROP USER,DROP ROLE,DROP QUOTA,DROP [ROW] POLICY,DROP [SETTINGS] PROFILE - ASTDropQuery:
其中包含了三种不同的删除操作(Drop/Truncate/Detach),Detach Table和Attach Table对应,它是表的卸载动作,把表的存储目录整个移到专门的detach文件夹下,然后关闭表在节点RAM中的”引用”,这张表在节点中不再可见。 - ASTGrantQuery:
这是授权相关的RBAC,可以对库/表授予或者撤销读/写等权限命令,例如GRANT insert on db.tb to acount,或者REVOKE all on db.tb from account。 - ASTKillQueryQuery:
可以Kill正在运行的Query,也可以Kill之前发送的Mutation命令。 - ASTOptimizeQuery:
这是MergeTree表引擎特有的操作命令,它可以手动触发MergeTree表的合并动作,并可以强制数据分区下的所有Data Part合并成一个。 - ASTRenameQuery:
修改表名,可更改到不同库下。
DDL Query Task分发
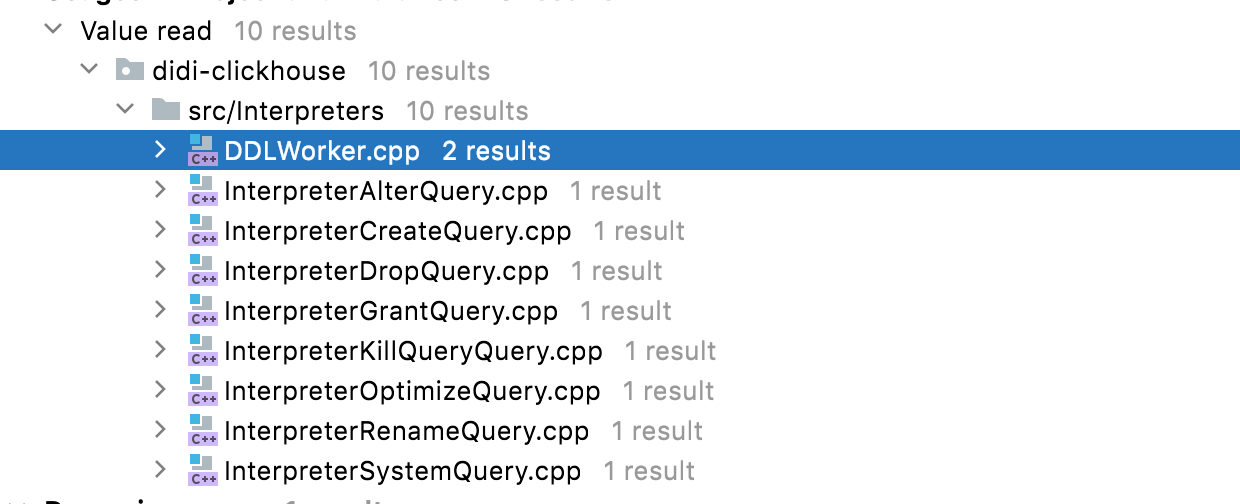
ClickHouse内核对每种SQL操作都有对应的IInterpreter实现类,其中的execute方法负责具体的操作逻辑。而以上列举的ASTQuery对应的IInterpreter实现类中的execute方法都加入了分布式DDL执行判断逻辑,把所有分布式DDL执行链路统一都DDLWorker::executeDDLQueryOnCluster方法中。executeDDLQueryOnCluster的过程大致可以分为三个步骤:
检查DDLQuery的合法性,
- 1、校验query规则
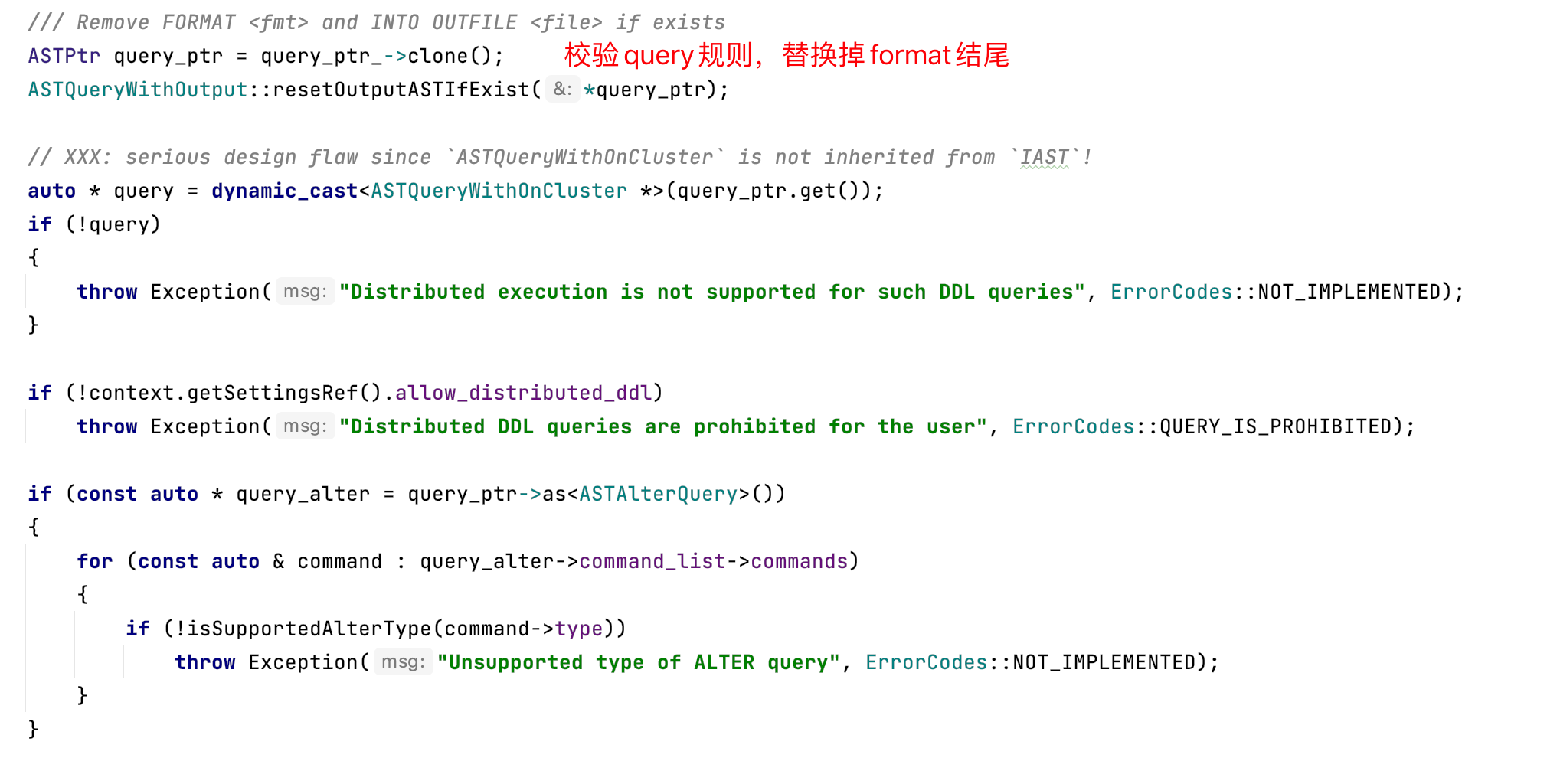
- 2、初始化DDLWorker,取config.xml表的配置

- 3、替换query里的数据库名称

这里替换库名的逻辑是, - 3.1、如果query里有带上库名称,则直接使用,若无,则走2
- 3.2、metrika.xml里配置了shard的默认库
<default_database>default</default_database>,则使用默认库,否则走3 - 3.3、使用当前session的database

把DDLQuery写入到Zookeeper任务队列中
- 1、构造DDLLogEntry对象,把entry对象加入到queue队列中

注意:queue_dir是由config.xml配置的,如下1
2
3<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl> - 2、去zookeeper执行创建znode,把entry序列化存入znode

- 3、在znode下创建active和finished的znode
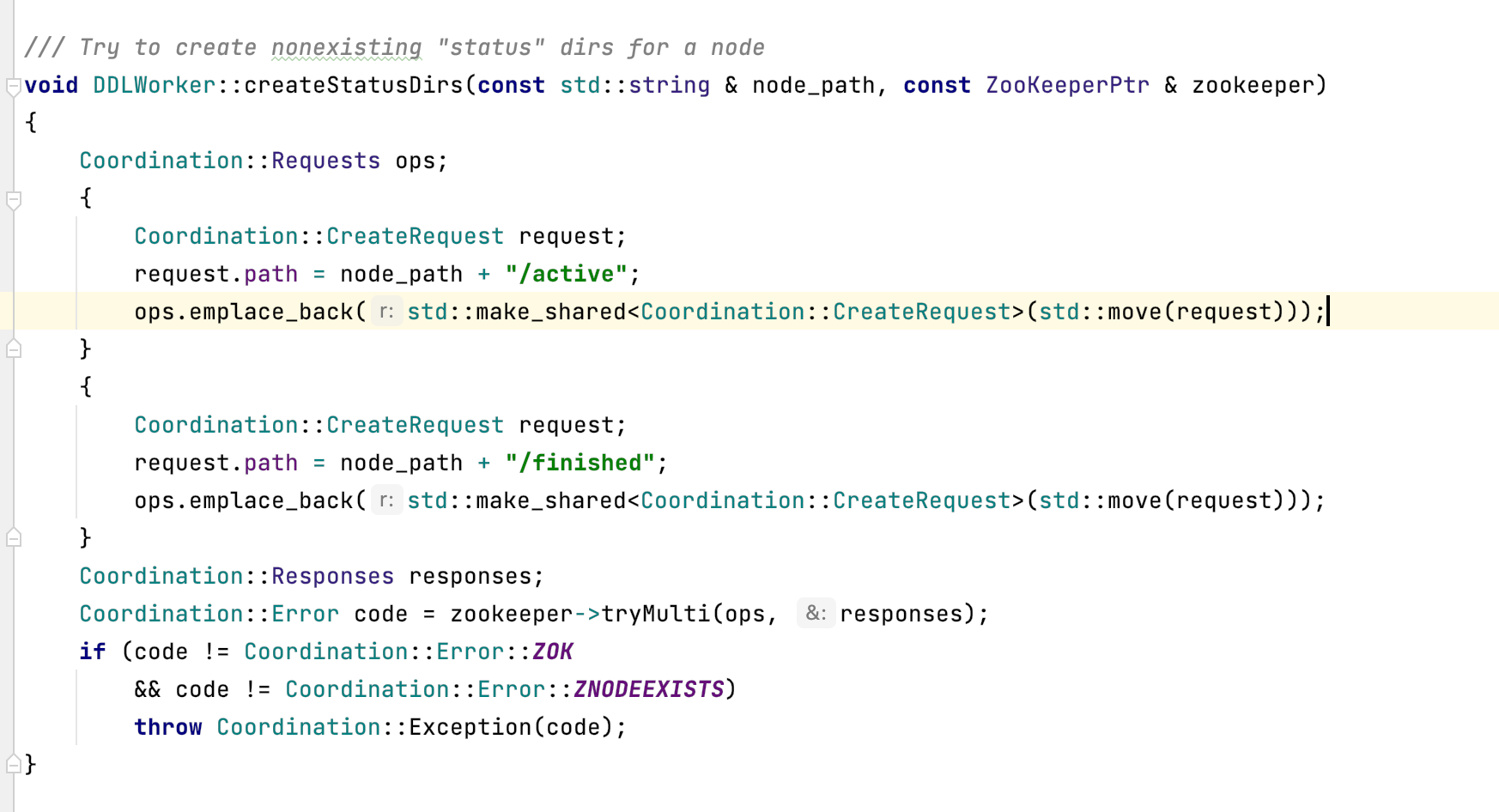
下面截图为query-xxx的记录的entry内容

等待Zookeeper任务队列的反馈把结果返回给用户。

DDL Query Task执行线程
- 1、DDLWorker构造函数去取了config.xml配置,并且开启了2个线程,分别是执行线程和清理线程

- 2、执行线程加入到线程池后,执行ddl task

- 3、过滤掉 query 中带有 on cluster xxx的语句,根据不同的query选择不同执行方式

- 4、alter、optimize、truncate语句需要在leader节点执行

注意:Replcated表的alter、optimize、truncate这些query是会先判断是否leader节点,不是则不处理,在执行时,会先给zookeeper加一个分布式锁,锁住这个任务防止被修改,执行时都是把自己的host:port注册到znode/query-xxx/active下,执行完成后,结果写到znode/query-xxx/finished下。
DDL Query Task清理线程
- 1、DDLWorker构造函数去取了config.xml配置,并且开启了2个线程,分别是执行线程和清理线程
- 2、执行清理逻辑,每次执行后,下一次执行需要过1分钟后才可以接着做清理

分布式DDL的执行链路总结
1)节点收到用户的分布式
DDL请求2)节点校验分布式DDL请求合法性,在
Zookeeper的任务队列中创建Znode并上传DDL LogEntry(query-xxxx),同时在LogEntry的Znode下创建active和finish两个状态同步的Znode3)
Cluster中的节点后台线程消费Zookeeper中的LogEntry队列执行处理逻辑,处理过程中把自己注册到acitve Znode下,并把处理结果写回到finish Znode下4)用户的原始请求节点,不断轮询
LogEntry Znode下的active和finish状态Znode,当目标节点全部执行完成任务或者触发超时逻辑时,用户就会获得结果反馈
这个分发逻辑中有个值得注意的点:分布式DDL执行链路中有超时逻辑,如果触发超时用户将无法从客户端返回中确定最终执行结果,需要自己去Zookeeper上check节点返回结果(也可以通过system.zookeeper系统表查看)。每个节点只有一个后台线程在消费执行DDL任务,碰到某个DDL任务(典型的是optimize任务)执行时间很长时,会导致DDL任务队列积压从而产生大面积的超时反馈。
可以看出Zookeeper在分布式DDL执行过程中主要充当DDL Task的分发、串行化执行、结果收集的一致性介质。