什么是CRUD
CRUD是指在做计算处理时的增加(Create)、检索(Retrieve)、更新(Update)和删除(Delete)几个单词的首字母简写。crud主要被用在描述软件系统中数据库或者持久层的基本操作功能
clickhouse物理上的crud
- create创建表
1
2
3
4
5
6
7
8
9
10
11create table account(
time DateTime default now() comment '创建时间',
name String default '' comment '唯一标示',
alias String default '' comment '别名',
age UInt64 default 0 comment '年龄',
version UInt64 default 0 comment '版本号',
is_delete UInt8 default 0 comment '是否删除,0否,1是'
)
engine = MergeTree
partition by toYYYYMMDD(time)
order by name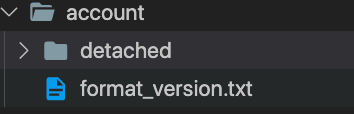
- create创建表
- insert写入数据
1
insert into default.account(time, name, alias, age, version, is_delete) values ('2022-01-01 11:11:11', 'blanklin', 'superhero', 20, 1, 0)
写入数据后会按照partitionby生成对应的分区part目录
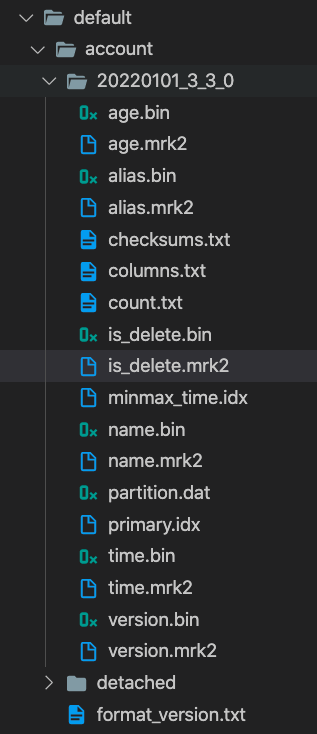
- insert写入数据
- update更新
1
2
3alter table default.account
update alias = 'super_hero'
where alias = 'superhero'这里是 mutation 操作,会生成一个mutation_version.txt
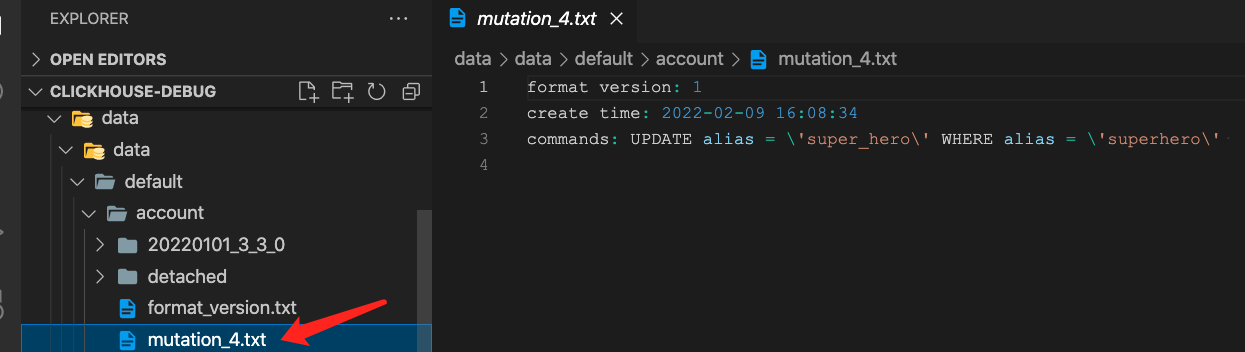
- update更新
- delete删除
1
alter table delete where id = 1
这里是 mutation 操作,会生成一个mutation_version.txt
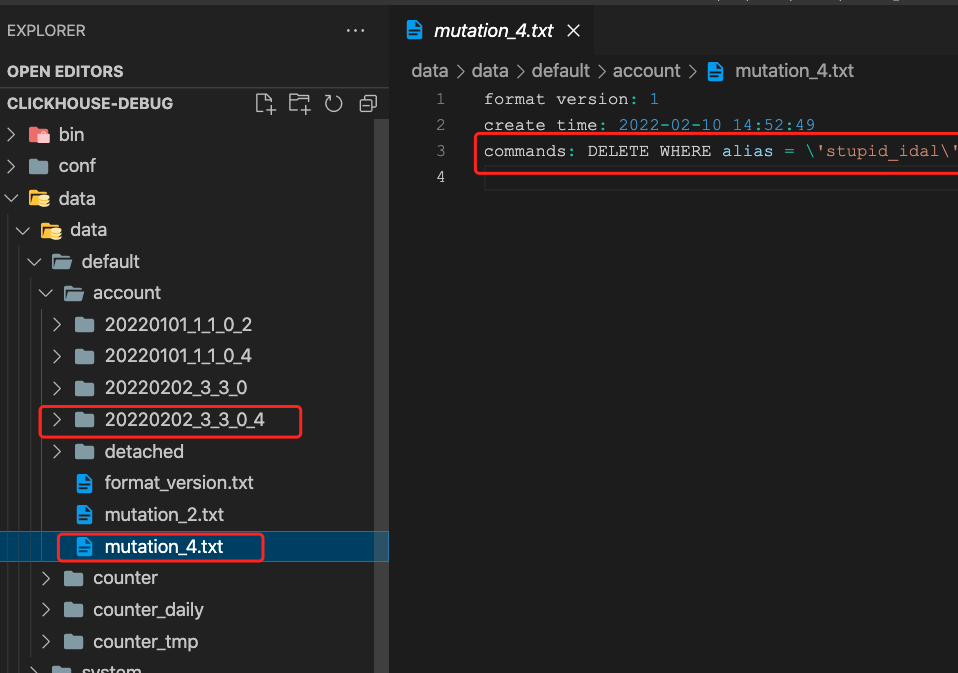
- delete删除
- retrieve检索
1
select time, name, alias, age, version, is_delete from account where is_delete = 0 order by version desc
- retrieve检索
- 可以通过system.mutations查询执行计划
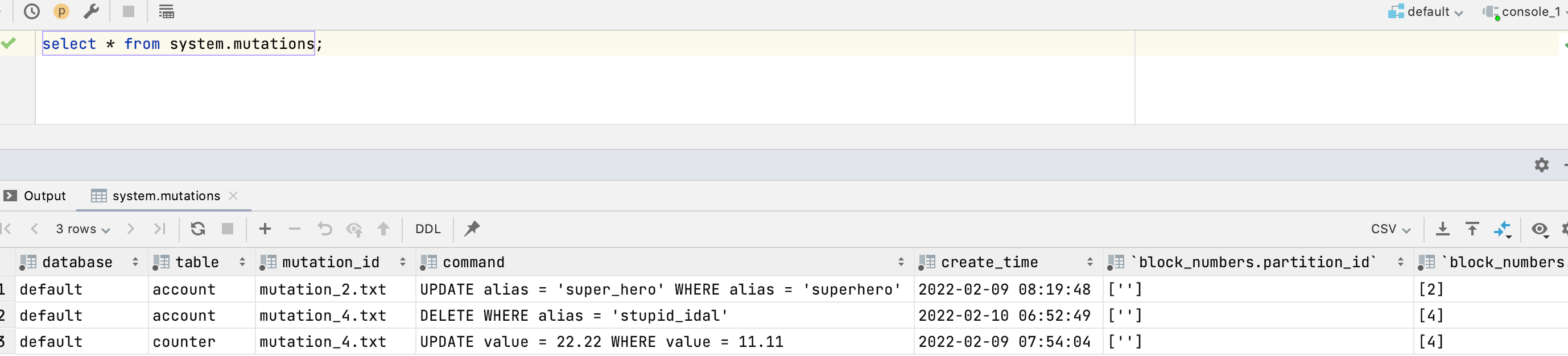
当mutation操作执行完成后,system.mutations表中对应的mutation记录中is_done字段的值会变为1。
- 可以通过system.mutations查询执行计划
- 可以通过system.parts查询执行结果
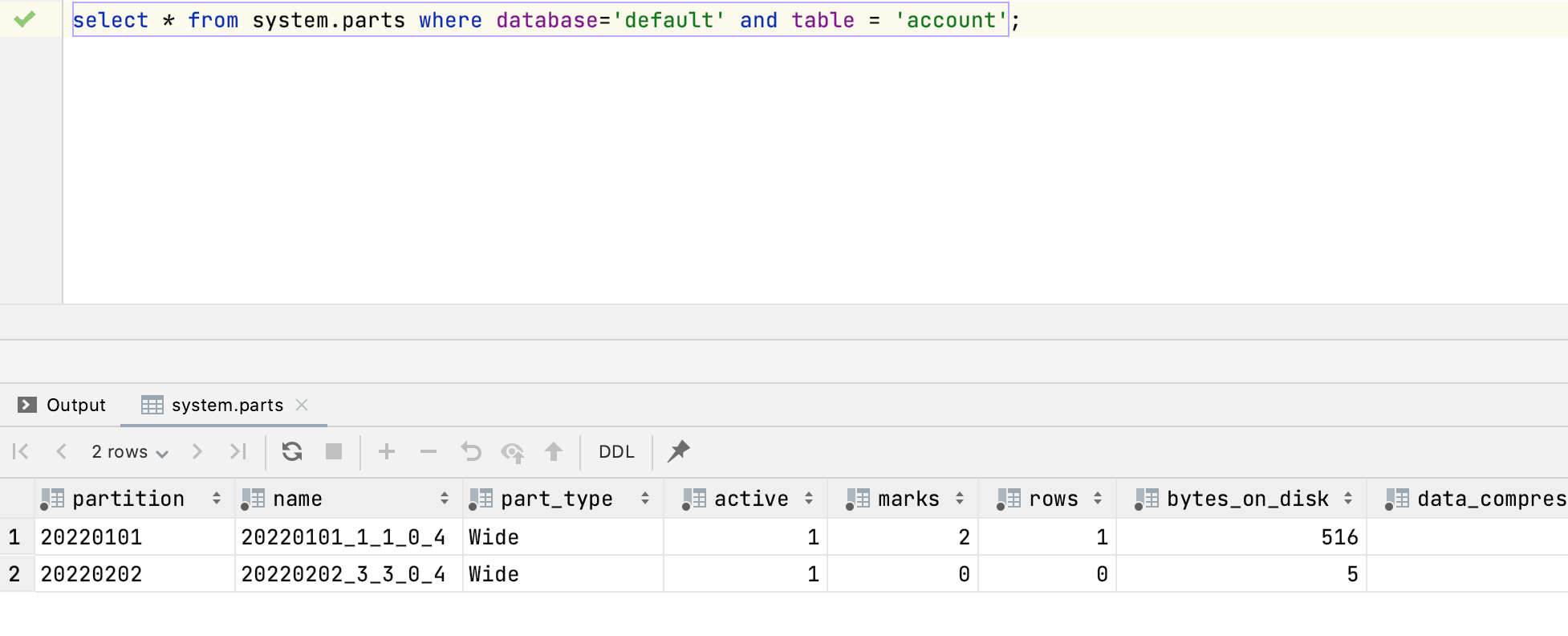
当旧的数据片段移除后,system.parts表中旧数据片段对应的记录会被移除。
- 可以通过system.parts查询执行结果
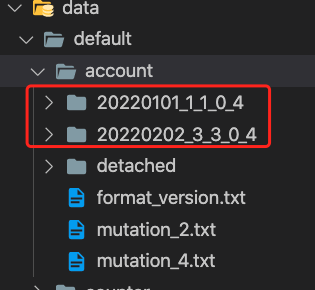
可以看到mutation操作完成后,之前的目录已经被删除
clickhouse的mutation是什么
官方文档解释
从官方对于mutaiton的解释链接中,我们需要注意到几个关键词,如下
- manipulate table data
操作表数据
- manipulate table data
- asynchronous background processes
异步后台处理
- asynchronous background processes
- rewriting whole data parts
重写全部数据part
- rewriting whole data parts
- a SELECT query that started executing during a mutation will see data from parts that have already been mutated along with data from parts that have not been mutated yet
在突变期间的查询语句,将看到已经完成突变的数据part和还未发生突变的part
- a SELECT query that started executing during a mutation will see data from parts that have already been mutated along with data from parts that have not been mutated yet
- data that was inserted into the table before the mutation was submitted will be mutated and data that was inserted after that will not be mutated
在提交突变之前插入表中的数据将被突变,而在此之后插入的数据将不会被突变
- data that was inserted into the table before the mutation was submitted will be mutated and data that was inserted after that will not be mutated
- There is no way to roll back the mutation once it is submitted, but if the mutation is stuck for some reason it can be cancelled with the KILL MUTATION query
突变一旦被提交就没有方式可以回滚,但是如果突变由于一些原因被卡住,可以使用KILL MUTATION取消突变
- There is no way to roll back the mutation once it is submitted, but if the mutation is stuck for some reason it can be cancelled with the KILL MUTATION query
源码解读
当用户执行一个如上的Mutation操作获得返回时,ClickHouse内核其实只做了两件事情:
- 检查Mutation操作是否合法;
主体逻辑在MutationsInterpreter::validate函数
- 检查Mutation操作是否合法;
- 保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;
主体逻辑在StorageMergeTree::mutate函数中。
- 保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;
Merge逻辑
StorageMergeTree::merge函数是MergeTree异步Merge的核心逻辑,Data Part Merge的工作除了通过后台工作线程自动完成,用户还可以通过Optimize命令来手动触发。自动触发的场景中,系统会根据后台空闲线程的数据来启发式地决定本次Merge最大可以处理的数据量大小,max_bytes_to_merge_at_min_space_in_pool: 决定当空闲线程数最大时可处理的数据量上限(默认150GB)
max_bytes_to_merge_at_max_space_in_pool: 决定只剩下一个空闲线程时可处理的数据量上限(默认1MB)
当用户的写入量非常大的时候,应该适当调整工作线程池的大小和这两个参数。当用户手动触发merge时,系统则是根据disk剩余容量来决定可处理的最大数据量。
Mutation逻辑
系统每次都只会订正一个Data Part,但是会聚合多个mutation任务批量完成,这点实现非常的棒。因为在用户真实业务场景中一次数据订正逻辑中可能会包含多个Mutation命令,把这多个mutation操作聚合到一起订正效率上就非常高。系统每次选择一个排序键最小的并且需要订正Data Part进行操作,本意上就是把数据从前往后进行依次订正。


mutation和merge相互独立执行。看完本文前面的分析,大家应该也注意到了目前Data Part的merge和mutation是相互独立执行的,Data Part在同一时刻只能是在merge或者mutation操作中。对于MergeTree这种存储彻底Immutable的设计,数据频繁merge、mutation会引入巨大的IO负载。实时上merge和mutation操作是可以合并到一起去考虑的,这样可以省去数据一次读写盘的开销。对数据写入压力很大又有频繁mutation的场景,会有很大帮助
clickhouse逻辑CRUD
VersionedCollapsingMergeTree介绍,引擎继承自 MergeTree 并将折叠行的逻辑添加到合并数据部分的算法中。 VersionedCollapsingMergeTree 用于相同的目的 折叠树 但使用不同的折叠算法,允许以多个线程的任何顺序插入数据。 特别是, Version 列有助于正确折叠行,即使它们以错误的顺序插入。 相比之下, CollapsingMergeTree 只允许严格连续插入。
创建VersionedCollapsingMergeTree表
1 | create table test_version_collapsing( |
插入数据
1 | insert into default.test_version_collapsing(time, name, alias, age, version, sign) values ('2022-01-01 11:11:11', 'blanklin', 'superhero', 20, 1, 1) |
更新数据
- 先找出要更新的这条数据
1
2select time, name, alias, age, version, sign from default.test_version_collapsing
where name = 'blanklin' and sign = 1
- 先找出要更新的这条数据
- 假设要更新alias=update_super_hero,其他值不变,将version由1.捞出的值上+1,类似以下sql
1
2
3
4
5# 先将旧行标示为删除,就是将sign = -1
insert into default.test_version_collapsing(time, name, alias, age, version, sign) values ('2022-01-01 11:11:11', 'blanklin', 'superhero', 20, 1, -1);
# 再去插入新行,包含要更新的列
insert into default.test_version_collapsing(time, name, alias, age, version, sign) values ('2022-01-01 11:11:11', 'blanklin', 'update_superhero', 20, 2, 1).
- 假设要更新alias=update_super_hero,其他值不变,将version由1.捞出的值上+1,类似以下sql
- 捞出更新后的那条数据
1
select name, argMax(age, version), argMax(alias, version) from default.test_version_collapsing group by name having sum(sign) > 0;
- 捞出更新后的那条数据
删除数据
- 先找出要更新的这条数据
1
2select time, name, alias, age, version, sign from default.test_version_collapsing
where name = 'blanklin' and sign = 1
- 先找出要更新的这条数据
- 假设要删除alias=update_super_hero,其他值不变,将sign=1,类似以下sql
1
insert into default.test_version_collapsing(time, name, alias, age, version, sign) values ('2022-01-01 11:11:11', 'blanklin', 'update_superhero', 20, 2, -1)
- 假设要删除alias=update_super_hero,其他值不变,将sign=1,类似以下sql
- 捞出更新后的那条数据
1
select name, argMax(age, version), argMax(alias, version) from default.test_version_collapsing group by name having sum(sign) > 0;
- 捞出更新后的那条数据
注意项
- 只有相同分区内的数据才能删除和更新
- 如果不使用 having sum(sign) > 0的方式去查询,则可以使用
final方式查询1
select * from test_version_collapsing final;
- 如果不使用 having sum(sign) > 0的方式去查询,则可以使用
- 也可以使用
optimize方式强制合并分区,再查询,但是这个方式可能会造成集群cpu飙高,而且optimize一个大表需要时间很长,效率极低1
optimize table test_version_collapsing final
- 也可以使用
- sign必须要唯一,添加用1,则删除一定是-1,才可以被折叠处理