请求处理
ck请求处理过程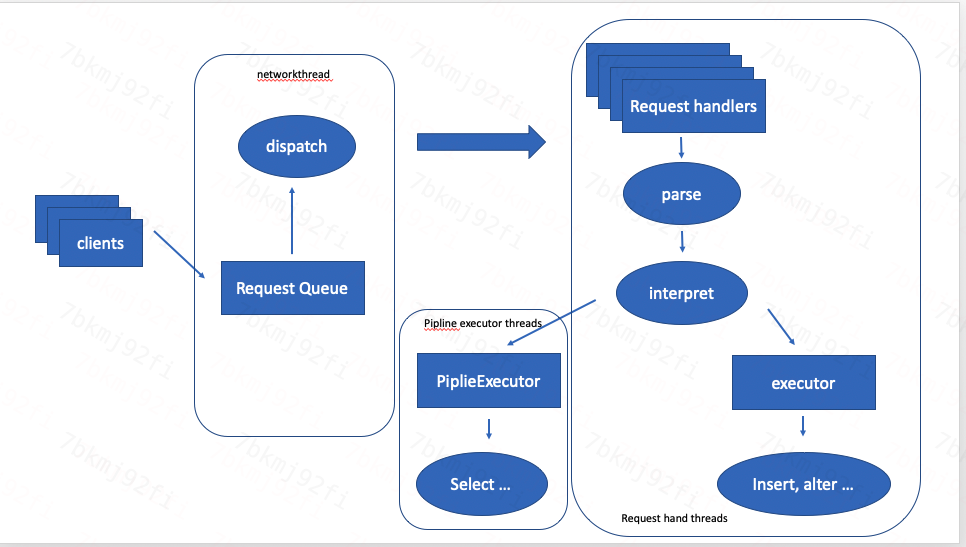
客户端请求发给ck,ck接收到请求,放入请求队列
ck将请求队列的请求分发给Request handler线程处理
Request handler线程处理请求,解析sql语句,执行sql语句逻辑。
简单请求处理使用Request handler线程直接执行(如create,insert,alter等), 复杂请求处理使用Pipeline executor执行(如select, insert select等)
请求线程处理完当前请求后,发送请求结果给给客户端。然后接着处理后续请求
insert语句解析执行
初始化请求上下文环境。包括session,用户信息,当前database等,限流,权限,设置等信息
解析sql语句
检查被写入的表是否存在,是否有写入权限,是否被限流
对insert数据校验,字段是否存在,是否满足约束
根据默认值填充空字段和物化字段
缓存单次insert语句中的数据,insert语句全部接收完成或缓存数据超过一定大小后批量写入数据。
将insert的数据写入存储引擎,主要包含StorageDistributed和StorageReplicatedXXMergeTree
检查是否有物化视图,如果有使用物化视图逻辑处理insert数据,写入物化视图表
分布式表写入
分布式表数据写入一般情况下是异步写入,只有对使用 remote(‘addresses_expr’, db, table[, ‘user’[, ‘password’], sharding_key]) 定义的表的写入是同步的。如果分布式表中含有local表或replical的表local副本,直接写本地表。
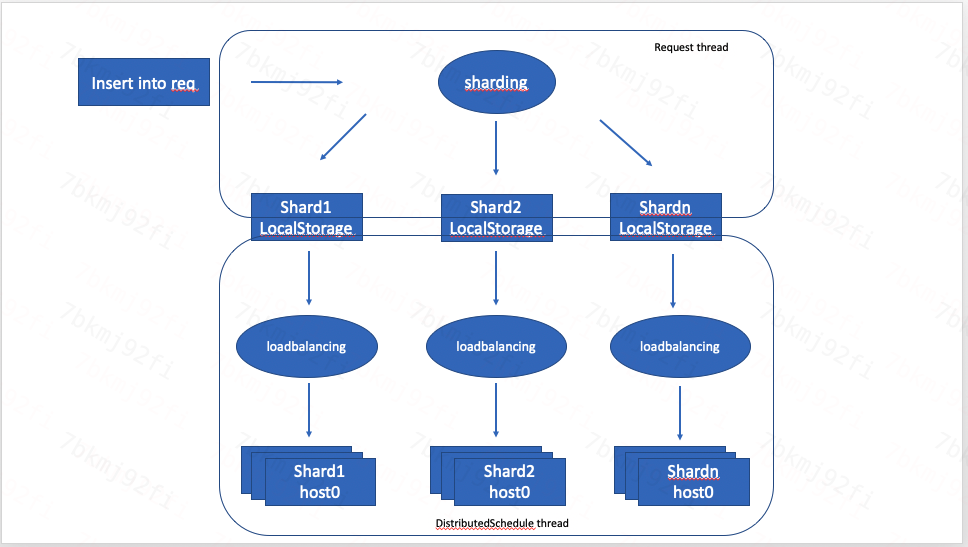
将写入block数据按sharding逻辑分成多个block
将原insert语句改写,表名改成分布式表对应的底表,数据改成分shard后的block数据
检查待写入的每个shard,如果shard在本机,则直接写入实际存储引擎
shard在远程,将新insert语句写入远程shard本地缓存文件。
通知后台线程发送本地缓存中的数据
后台执行过程
读远程shard本地缓存目录
逐个处理每个文件
根据配置的loadbalance策略,选择合适的机器连接
将文件的insert语句通过上步连接发送给远程机器执行
执行成功后删除对应文件
本地表写入
本地表一般是StorageReplicatedXXMergeTree,其写入过程如下:
本地表是以block为最小单元单次写入,一个block中的数据可能是一次insert的全部数据,也可以是部分数据。
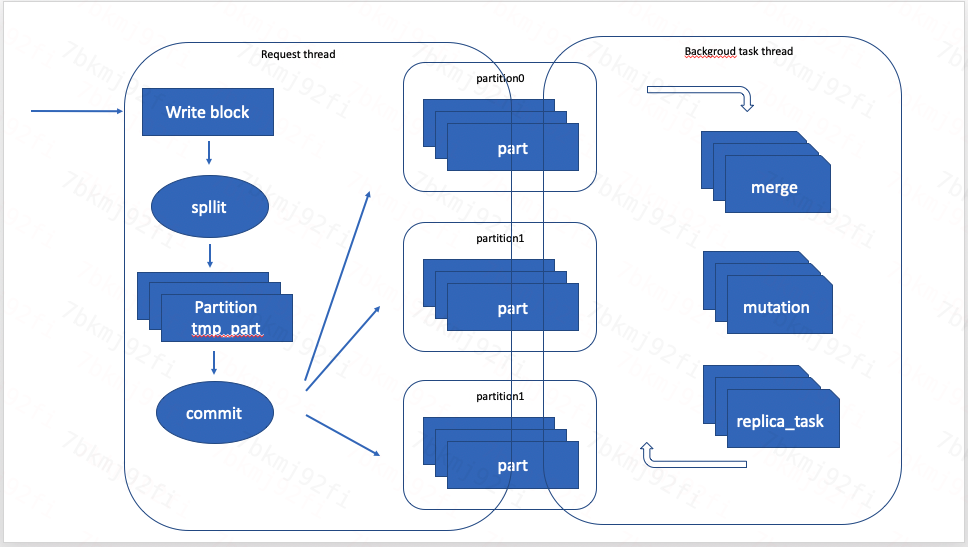
检查当前表part数量,如果part数量过多(接近part数限制)延时写入数据,如果part数量过限制则写入失败。
检查写入block中parttition总数是否超过限制。如果超过限制,写入失败。
将写入block数据按partition by 逻辑分成多个block
依次将每个分区的block数据写入表中
创建分区的临时part
计算part数据的sha1生成part对应的blockid
检查该blockid在是否存在(表的zk中会记录所有已存在的part的blockid)。如果存在表示插入数据重复,忽略后续步骤。
将part信息发布到ck,通知其他副本拉去新添加part
将临时part加入到commit到mergetree表
如果配置最小同步副本大于1,则等代其他副本数据同步达到满足条件
临时part创建过程
- 创建block数据对应分区的临时part对象
- 计算分区min_max索引
- 处理排序和主键索引
- ttl处理
- 其他二级索引处理
- 将处理过的block数据和索引写入临时part,根据配置的压缩方式压缩