背景介绍
clickhouse的Replicated**MergeTree表是通过zookeeper来完成同一个shard之间的副本数据的同步,因为clickhouse本身不是master/slave的架构,我们通过proxy的方式,设定了同一个shard里某个副本是读/写节点角色,另一个节点是读角色,当用户写入时,proxy会路由到读/写节点去完成写入操作,然后通过zk发起同步任务,把日志进入到system.replcation_queue。
今天早上用户和我们反馈说数据查询时每一次结果都不一样,用户查询也是通过连我们的proxy进行读节点的路由,所以用户反馈的结果不一致,其实是第一次路由到读/写节点查询结果是a,第二次路由到读节点,查询结果是b,由于a和b两个副本数据没有同步,导致了查询结果不一致,下面是排查的过程。
system.replication_queue
如官方地址所解释,该表记录了当前的副本任务队列的所有信息,如下图所示,我们看到当前副本同步出现大量异常错误
1 | select * from system.replication_queue where data_files > 0 |
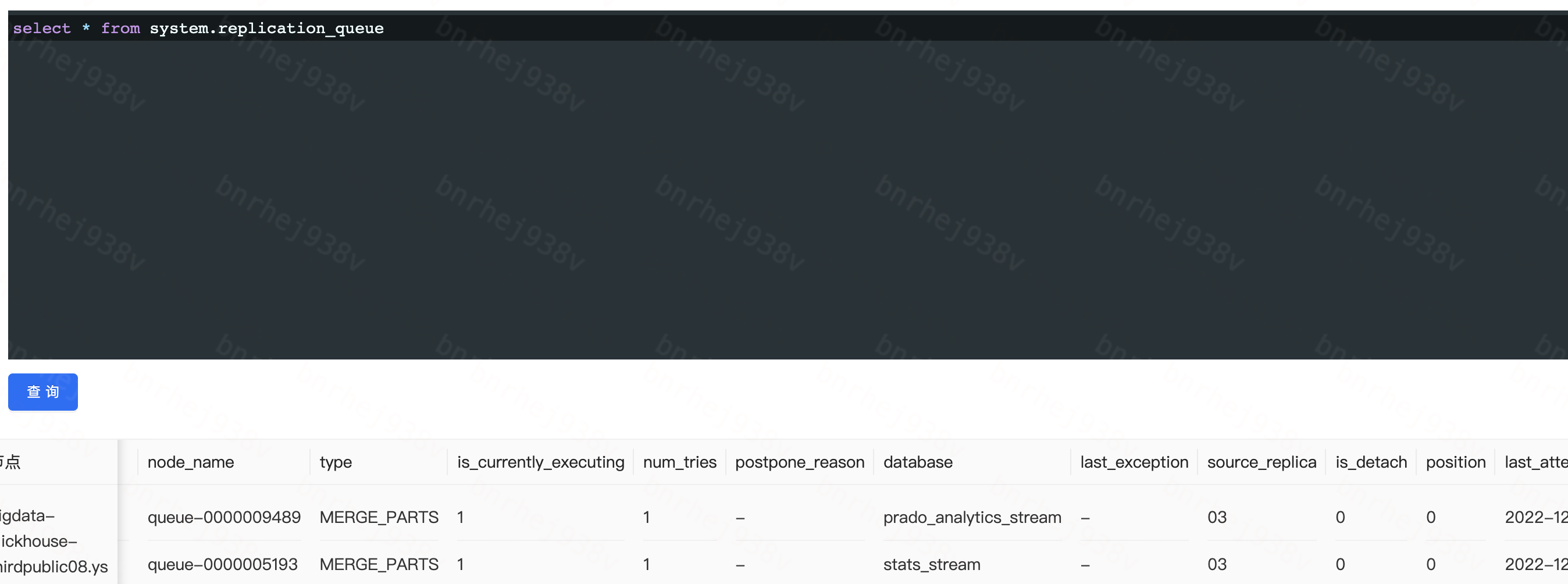
如下图所示,type字段可以查看到当前是什么类型的操作导致的,发现是MUTATE_PART操作,last_exception字段显示当前我们在操作ttl时创建的元数据目录下columns.txt无法打开,这个是已知bug。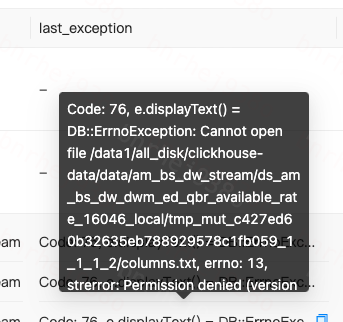
system.mutations
如官方地址,该表包含了所有mutation操作的日志信息,mutation操作包括修改字段类型/修改表ttl操作/按条件删表的数据/按条件更新表的数据等,这些操作都是异步后台线程去处理,都会去回溯该表的所有parts,需要rewrite每个part的信息并且这个操作还不是原子性的,所以如果某个节点操作失败,可能引发该表无法使用。
该表包含字段如下:
database (String) — 数据库名称.
table (String) — 表名称.
data_path (String) — 本地文件的路径.
mutation_id (String) — mutation的唯一标识,可通过该标识直接kill mutation.
command (String) — mutation命令.
create_time (DateTime) — mutation创建时间.
block_numbers (Map) — partition_id:需要进行mutation操作的分区id,number:需要进行mutation的分区对应的block序号.
parts_to_do_names (Array) — 即将完成的需要进行mutation的数组.
parts_to_do (Int64) — 准备进行mutation操作的part序号.
is_done (UInt8) — 该操作是否已完成.
latest_failed_part (String) — mutation操作最后失败的part名称.
latest_fail_time (DateTime) — 最后失败的时间.
latest_fail_reason (String) — 最后失败的原因.
1 | select * from system.mutations where latest_failed_part != '' |
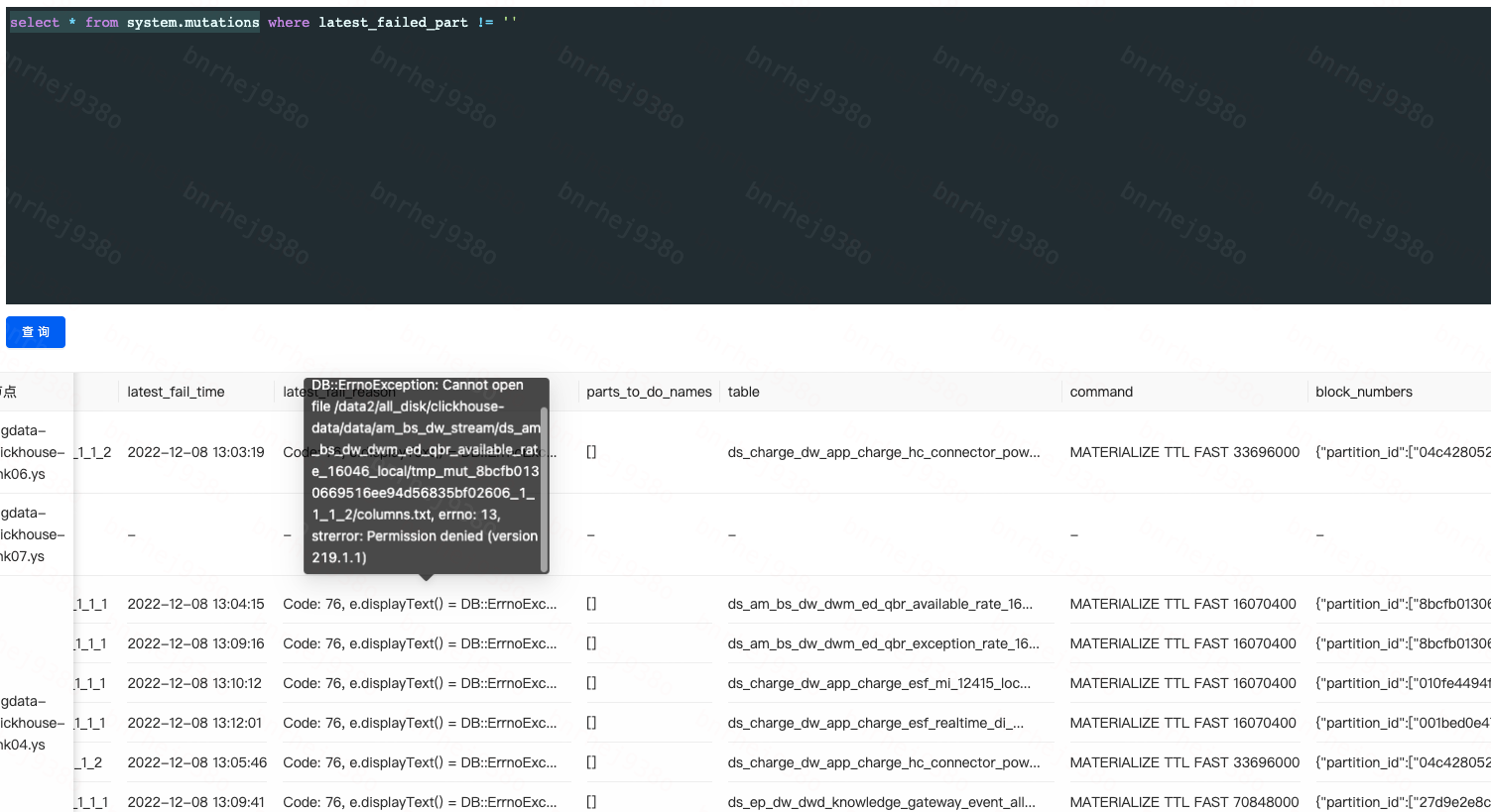
根据异常错误的command字段,我们看到错误是通过
MATERIALIZE TTL FAST 16070400引起的,mutation操作在写节点处理完成后,也会通过zookeeper进行副本数据同步
解决副本不同步问题
- 终止该失败的mutation
具体操作语句可以查看官方文档1
kill mutation where database = 'xx' and table = 'yy' and mutation_id = 'zz';
- 操作之后,可以通过查询shard里每个副本的count是否一致来判断数据是否已经进行同步
1
select count(dt), dt from xx.yy group by dt;
- 操作之后,可以通过上面的
system.replication_queue表来观察是否开始进行副本数据同步1
select * from system.replication_queue where type='GET_PART' and database = 'xx' and table = 'yy'
- 如果还没恢复,则去对应出错的副本节点,将本地表删除后重建(出错节点可以从上一步里看出来)
1
2drop table if exists xx.yy
create table xx.yy - 此时再查询replication_queue表出错的队列应该已经被清理掉了
可以继续操作元数据修改