背景介绍
- 什么是StarRocks
StarRocks是一款极速全场景MPP企业级数据库产品,具备水平在线扩缩容,金融级高可用,兼容MySQL协议和MySQL生态,提供全面向量化引擎与多种数据源联邦查询等重要特性。StarRocks致力于在全场景OLAP业务上为用户提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景。 - 滴滴olap现状
当前在滴滴内部,主要大数据olap生态包括clickhouse/druid/starrocks等,而写入olap可以划分为两个方向,分布是实时和离线:- 2.1 实时方向,包括网约车/金融等大部分业务侧均是使用kafka/ddmq作为source端,将数据通过flink实时攒批写入到大数据olap存储侧
- 2.2 离线方向,包括网约车/金融等大部分业务侧则是将数据通过hive/mysql/hdfs这个source端,经过各项加工后流入到olap这个sink存储侧
- 本文主题
本篇文章主要是介绍在starrocks这一侧,如果实现将hive数据进行加工后写入到starrock,涉及到starrokc的源码解析、组件介绍、及相关平台架构
架构设计
如下图,是当前滴滴内部hive2sr导入的实现架构图,用户主要是通过访问同步中心,配置hive表和sr表的字段映射及默认值,同步中心会将映射关系通过srm开放的http接口传给srm侧,srm进行相关处理后提交给sr的各个组件,组件之间通过thrift server进行rpc通信,而srm则通过http方式进行任务最终状态监听,当任务完成后返回给数梦的任务调度系统,最终完成整个全链路流程.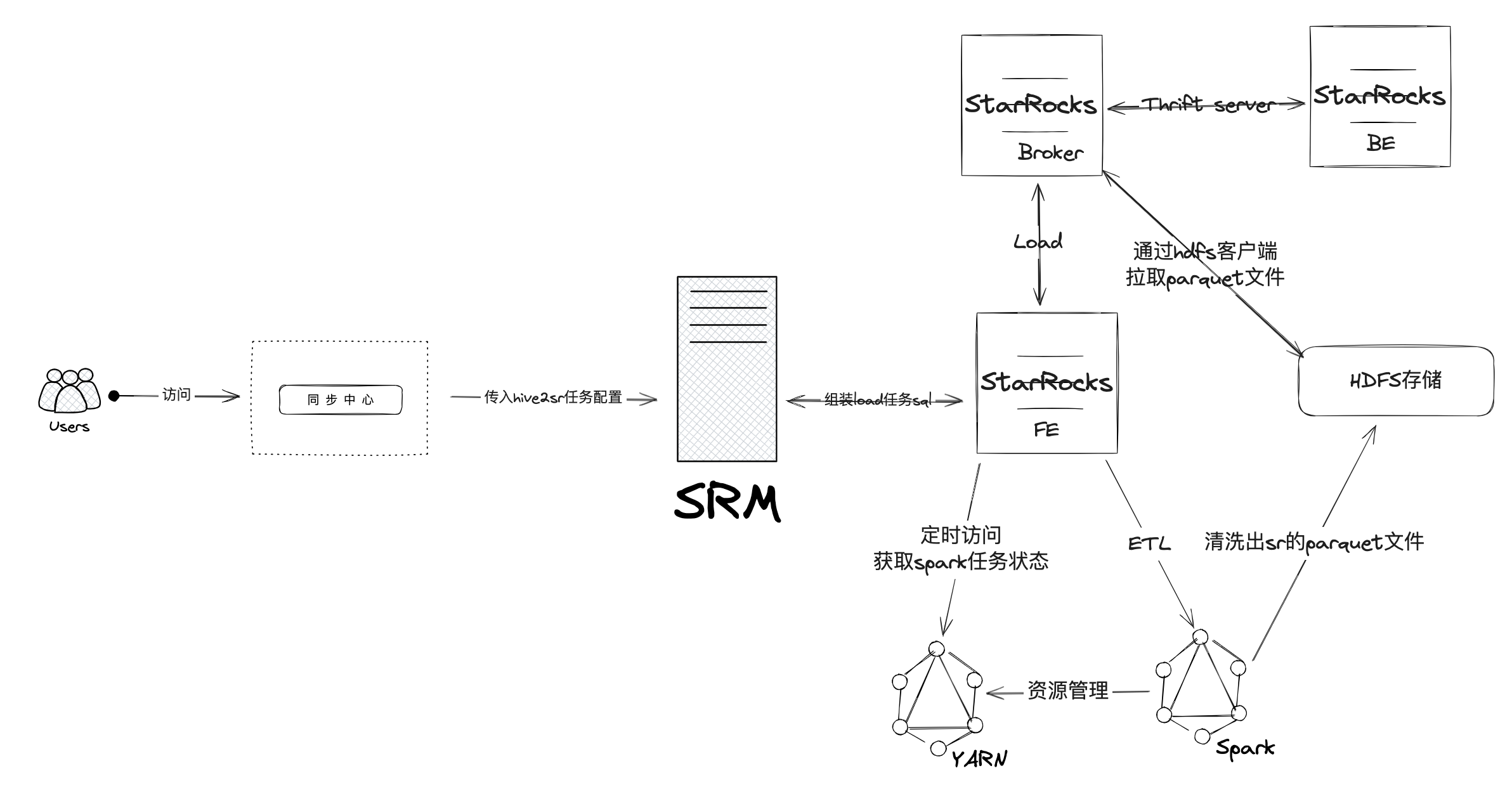
基本原理
- 创建目标分区
同步中心会将hive2sr当前批次需要导入hive的分区列表传入srm,srm会校验当前sr表对应分区是否存在,不存在则按照hive分区值对应创建出sr表分区 - 创建目标分区
上面这一步创建出目标分区后,srm会对应目标分区range范围,在sr目标表中创建出对应的临时分区,临时分区的作用是这样的,srm可以在一张已经定义分区规则的分区表上,创建临时分区,并为这些临时分区设定单独的数据分布策略。将hive数据写入指定的临时分区后,通过原子覆盖写操作(调整分区分桶策略),srm可以将临时分区作为临时可用的数据载体覆盖到对应的目标分区,用以实现覆盖写操作 - 创建load任务
3.1 这个load首先需要配置涉及sr访问hadoop环境的相关参数,这个操作相当于在sr中配置hdfs-site.xml和core-site.xml
3.2 其实load任务需要组装出提交给spark的driver任务内容,通过cluster模式,以master on yarn的方式在fe节点提交出spark任务 - fe进程调度etl阶段
在etl阶段,fe会开启spark driver等待yarn队列资源充足时,提交给yarn取执行spark任务,Spark集群执行ETL完成对导入数据的预处理。包括全局字典构建(BITMAP类型)、分区、排序、聚合等。预处理后的数据按parquet数据格式落盘HDFS存储侧。 - etl完成后fe会调度load阶段
ETL 任务完成后,FE获取预处理过的每个分片的hdfs数据路径,并调度相关的 broker 执行 load 任务 - broker加载hdfs文件后通知be进行push
BE 通过 Broker 进程读取 HDFS 数据,转化为 StarRocks 存储格式。此时临时分区完成对应hive分区数据的加载过程 - 将临时分区替换到目标分区
临时分区的数据将完成的替换到目标分区去,而目标分区数据将被删除,查询后将是新的hive分区数据
源码解析
fe进程启动及相关调度处理
入口文件->StarRocksFE.java
1
2
3
4.....
feServer.start();
httpServer.start();
qeService.start();主要是初始化配置和启动服务,分别是mysql server端口、thrift server端口、http端口
mysq服务启动->QeService.java
由于我们都是通过tcp协议来连sr,所以主要关注QeService1
2
3
4
5
6
7public void start() throws IOException {
if (!mysqlServer.start()) {
LOG.error("mysql server start failed");
System.exit(-1);
}
LOG.info("QE service start.");
}MysqlServer.java
这里主要是开启mysql协议的服务1
2
3
4
5
6
7
8
9public boolean start() {
......
// 打开fe的mysql协议的socket管道
// 开启一个常驻线程用以监听mysql协议
listener = ThreadPoolManager.newDaemonCacheThreadPool(1, "MySQL-Protocol-Listener", true);
running = true;
listenerFuture = listener.submit(new Listener());
......
}提交本次连接的上下文到连接调度器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19........
clientChannel = serverChannel.accept();
if (clientChannel == null) {
continue;
}
// 初始化本次session的上下文信息到连接调度器
// submit this context to scheduler
ConnectContext context = new ConnectContext(clientChannel, sslContext);
// Set globalStateMgr here.
context.setGlobalStateMgr(GlobalStateMgr.getCurrentState());
if (!scheduler.submit(context)) {
LOG.warn("Submit one connect request failed. Client=" + clientChannel.toString());
// clear up context
context.cleanup();
}
............
```
+ 提交本次连接的上下文给线程池public boolean submit(ConnectContext context) {
if (context == null) {return false;}
context.setConnectionId(nextConnectionId.getAndAdd(1));
// no necessary for nio.
if (context instanceof NConnectContext) {return true;}
// 这里是将Runnable提交到connect-scheduler-pool线程池
if (executor.submit(new LoopHandler(context)) == null) {LOG.warn("Submit one thread failed."); return false;}
return true;
}1
2
+ LoopHandler.java (实现Runnable接口)public void run() {
…..
// 注册本次连接,sr会计算当前fe节点总的连接数,在每次连接超过1024后进行sleep连接的驱逐流程
if (registerConnection(context)) {MysqlProto.sendResponsePacket(context);} else {
context.getState().setError("Reach limit of connections"); MysqlProto.sendResponsePacket(context); return;}
………
// 常驻,进行核心sql的parser-》analyze-》rewrite-》logical plan-》optimizer-》physical plan
ConnectProcessor processor = new ConnectProcessor(context);
processor.loop();
……….
}1
2
+ ConnectProcessor.java -> looppublic void loop() {
while (!ctx.isKilled()) {try { processOnce(); } catch (Exception e) { // TODO(zhaochun): something wrong LOG.warn("Exception happened in one seesion(" + ctx + ").", e); ctx.setKilled(); break; }}
}1
2
+ ConnectProcessor.java -> processOnce// handle one process
public void processOnce() throws IOException {
// 重置上下文的状态
ctx.getState().reset();
executor = null;// 重置mysql协议的顺序标识符
final MysqlChannel channel = ctx.getMysqlChannel();
channel.setSequenceId(0);
// 从通道里获取数据包
try {packetBuf = channel.fetchOnePacket(); if (packetBuf == null) { throw new IOException("Error happened when receiving packet."); }} catch (AsynchronousCloseException e) {
// when this happened, timeout checker close this channel // killed flag in ctx has been already set, just return return;}
// 调度,这里主要是上面介绍核心sql的parser-》analyze-》rewrite-》logical plan-》optimizer-》physical plan过程
dispatch();
………….
}1
2
+ ConnectProcessor.java -> dispatch…….
// 这里主要是实现mysql协议的几种状态
switch (command) {
case COM_INIT_DB:handleInitDb(); break;case COM_QUIT:
handleQuit(); break;case COM_QUERY:
// 这里是完整的sql处理的总入口handleQuery(); ctx.setStartTime(); break;case COM_FIELD_LIST:
handleFieldList(); break;case COM_CHANGE_USER:
handleChangeUser(); break;case COM_RESET_CONNECTION:
handleResetConnnection(); break;case COM_PING:
handlePing(); break;default:
ctx.getState().setError("Unsupported command(" + command + ")"); LOG.warn("Unsupported command(" + command + ")"); break;}
……1
2
+ ConnectProcessor.java -> handleQuery….
StatementBase parsedStmt = null;
try {
ctx.setQueryId(UUIDUtil.genUUID());
Liststmts;
try {//通过antlr4进行sql的解析,获取sql解析ast树列表 stmts = com.starrocks.sql.parser.SqlParser.parse(originStmt, ctx.getSessionVariable());} catch (ParsingException parsingException) {
throw new AnalysisException(parsingException.getMessage());}
// 对ast语法树进行analyze分析过程
for (int i = 0; i < stmts.size(); ++i) {.......... // Only add the last running stmt for multi statement, // because the audit log will only show the last stmt. if (i == stmts.size() - 1) { addRunningQueryDetail(parsedStmt); } executor = new StmtExecutor(ctx, parsedStmt); ctx.setExecutor(executor); ctx.setIsLastStmt(i == stmts.size() - 1); executor.execute(); // 如果sql有一条执行失败,后续不再执行 if (ctx.getState().getStateType() == QueryState.MysqlStateType.ERR) { break; } ........}
}
….
1 | #### 对sql进行Parser语法解析 |
// 首先,我们需要初始化 StarRocksLexer,即词法解析器。在这里,StarRocksLexer 是根据上文介绍的StarRocksLex.g4 词法文件,使用 Antlr4 自动生成的代码类。
StarRocksLexer lexer = new StarRocksLexer(new CaseInsensitiveStream(CharStreams.fromString(sql)));
lexer.setSqlMode(sessionVariable.getSqlMode());
// 然后,代码将词法解析器 StarRocksLexer 作为参数,传入语法解析器中。语法解析器类StarRocksParser,同样是根据上文介绍的 StarRocks.g4 语法文件自动生成的代码类。
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
StarRocksParser parser = new StarRocksParser(tokenStream);
// 到这里,我们就完成了语法解析类的构建。之后再调用 parser.addErrorListener(new ErrorHandler()),将 Antlr4 的默认错误处理规则,替换为自定义的错误处理逻辑即可。
parser.removeErrorListeners();
parser.addErrorListener(new ErrorHandler());
parser.removeParseListeners();
parser.addParseListener(new TokenNumberListener(sessionVariable.getParseTokensLimit(),
Math.max(Config.expr_children_limit, sessionVariable.getExprChildrenLimit())));
……
List
// 调用 parser.sqlStatements() 返回值 StarRocksParser.SqlStatementsContext,这是一套 antlr 自定义的抽象语法树,根据语法文件生成。
List
for (int idx = 0; idx < singleStatementContexts.size(); ++idx) {
// 将 antlr 的语法树转换为 StarRocks 的抽象语法树
StatementBase statement = (StatementBase) new AstBuilder(sessionVariable.getSqlMode())
.visitSingleStatement(singleStatementContexts.get(idx));
statement.setOrigStmt(new OriginStatement(sql, idx));
statements.add(statement);
}1
2
3
+ StarRocks.g4 -> loadStatement
因为本文主要介绍的导入流程,所以以LoadStatement来举例
loadStatement
: LOAD LABEL label=labelName
data=dataDescList?
broker=brokerDesc?
(BY system=identifierOrString)?
(PROPERTIES props=propertyList)?
| LOAD LABEL label=labelName
data=dataDescList?
resource=resourceDesc
(PROPERTIES props=propertyList)?
;1
2
3antlr 的语法文件采用 BNF 范式,用'|'表示分支选项,'?'表达0次或一次,其他符号可类比正则表达式。
+ AstBuilder.java -> visitLoadStatement
Antlr4 会根据语法文件生成一份 Visitor 模式的代码,这样就可以做到动作代码与文法产生式解耦,利于文法产生式的重用。而自定义的 AstBuilder 文件则继承了 StarRocksBaseVisitor,用于将 antlr 内部的 AST 翻译成 StarRocks 自定义的 AST。
public ParseNode visitLoadStatement(StarRocksParser.LoadStatementContext context) {
// 解析出load里写的label名称
LabelName label = getLabelName(context.labelName());
// 解析出load里的字段映射默认值配置等描述
List
if (context.data != null) {
dataDescriptions = context.data.dataDesc().stream().map(this::getDataDescription)
.collect(toList());
}
// 解析出load里关于spark任务配置的property属性
Map
if (context.props != null) {
properties = Maps.newHashMap();
List
for (Property property : propertyList) {
properties.put(property.getKey(), property.getValue());
}
}
// 解析出load里引用的spark外部资源名称
if (context.resource != null) {
ResourceDesc resourceDesc = getResourceDesc(context.resource);
return new LoadStmt(label, dataDescriptions, resourceDesc, properties);
}
// 解析出broker的配置
BrokerDesc brokerDesc = getBrokerDesc(context.broker);
String cluster = null;
if (context.system != null) {
cluster = ((Identifier) visit(context.system)).getValue();
}
// visit 的返回值返回一个 AST 的基类,在StarRocks 中称为 ParseNode
return new LoadStmt(label, dataDescriptions, brokerDesc, cluster, properties);
}1
2
3
4
5我们对 Parser 源码进行了重点分析,包括 ANTLR4、SqlParser 和 ASTBuilder。与此同时,我们还通过一个例子,介绍了如何将一条文本类型的 SQL 语句,一步步解析成 StarRocks 内部使用的 AST。
可以看到,Parser 能判断出用户的 SQL 中是否存在明显的语法错误,如 SQL 语句select * from;会在Parser 阶段报错。但如果 SQL 语句select * from foo;没有语法错误,StarRocks 中也没有 foo 这张表,那么 StarRocks 该如何做到错误处理呢?这就需要依赖下一节的 Analyzer 模块去判断了。
#### 对sql进行analyzer语法解析
+ StmtExecutor.java-> executor
……..
// 本文主要介绍load流程,所以这里值关注ddl的词法分析过程
} else if (parsedStmt instanceof DdlStmt) {
handleDdlStmt();
}
……1
2
+ StmtExecutor.java -> handleDdlStmt
private void handleDdlStmt() {
if (parsedStmt instanceof ShowStmt) {
com.starrocks.sql.analyzer.Analyzer.analyze(parsedStmt, context);
PrivilegeChecker.check(parsedStmt, context);
QueryStatement selectStmt = ((ShowStmt) parsedStmt).toSelectStmt();
if (selectStmt != null) {
parsedStmt = selectStmt;
execPlan = StatementPlanner.plan(parsedStmt, context);
}
} else {
// 这里是analyze解析的入口函数
execPlan = StatementPlanner.plan(parsedStmt, context);
}
}1
2
+ StatementPlanner.java -> plan
// 注意在analyze阶段,也是会进行锁库操作(db.readLock();)
lock(dbs);
try (PlannerProfile.ScopedTimer ignored = PlannerProfile.getScopedTimer(“Analyzer”)) {
Analyzer.analyze(stmt, session);
}
PrivilegeChecker.check(stmt, session);
if (stmt instanceof QueryStatement) {
OptimizerTraceUtil.logQueryStatement(session, “after analyze:\n%s”, (QueryStatement) stmt);
}1
2
3Analyzer 类是所有语句的语义解析的主入口,采用了 Visitor 设计模式,会根据处理的语句类型的不同,调用不同语句的 Analyzer。不同语句的处理逻辑会包含在单独的语句 Analyzer 中,交由不同的 Analyzer 处理
+ LoadExecutor.java -> accept
public
return visitor.visitLoadStatement(this, context);
}1
2
3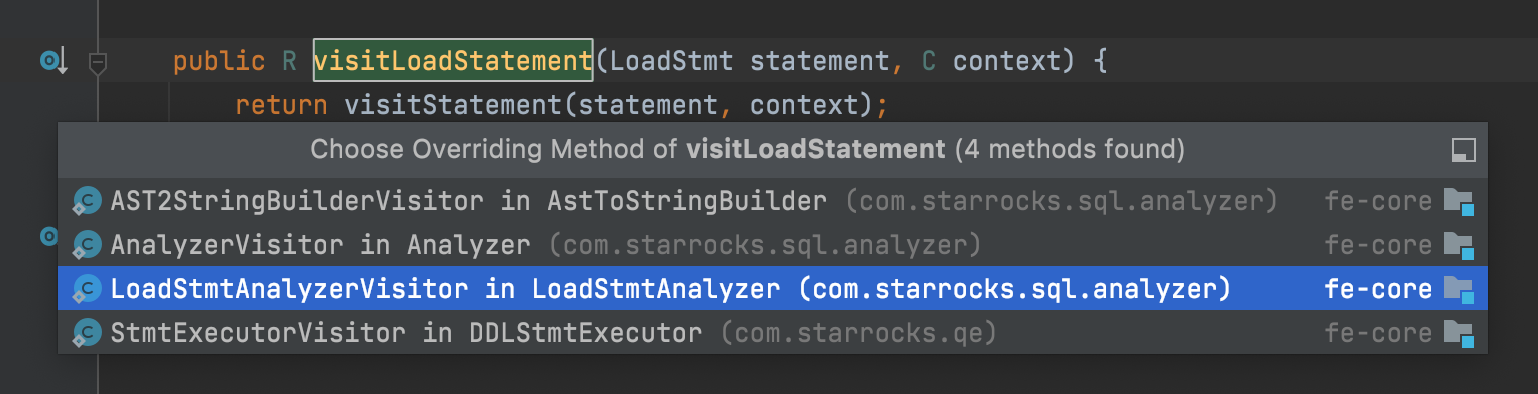
+ LoadStmtAnalyzer.java -> visitLoadStatement
public Void visitLoadStatement(LoadStmt statement, ConnectContext context) {
analyzeLabel(statement, context);
analyzeDataDescriptions(statement);
analyzeProperties(statement);
return null;
}1
2
3如上所示,LoadStatement交由LoadStmtAnalyzer来专门处理解析,这样做的优点是,可以将 Statement 的定义文件和 Analyze 的处理逻辑分开,并且同一类型的语句也交由特定的 Analyzer 处理,做到不同功能之间代码的解耦合。
+ StmtExecutor.java -> handleDdlStmt
private void handleDdlStmt() {
……..
// 这里是ddl 执行分析的总入口
ShowResultSet resultSet = DDLStmtExecutor.execute(parsedStmt, context);
……..
}1
2
+ DDLStmtExecutor.java -> execute
……..
// ddl statement analyze 处理逻辑的基类
return stmt.accept(StmtExecutorVisitor.getInstance(), context);
……..1
2
3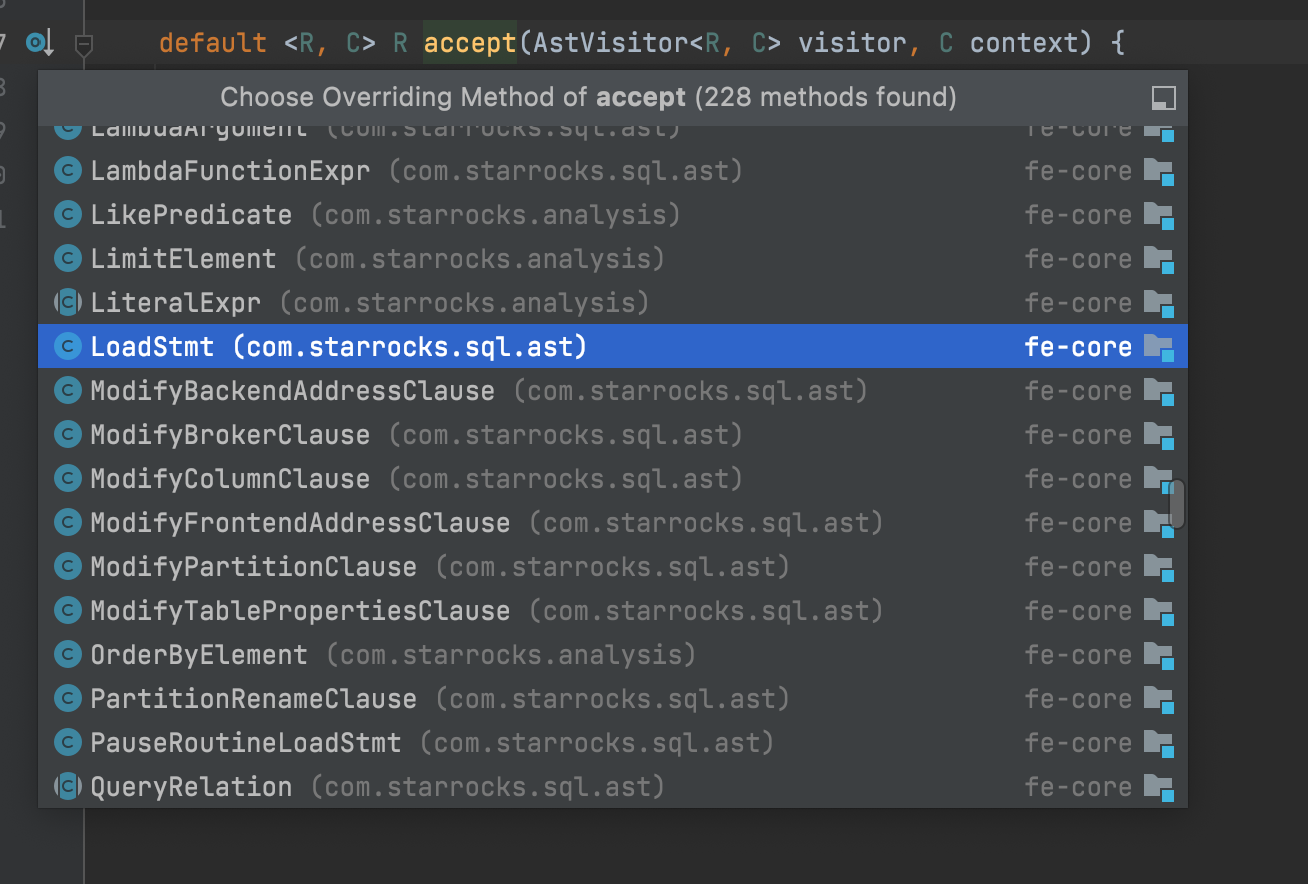
+ DDLStmtExecutor.java -> visitLoadStatement
public ShowResultSet visitLoadStatement(LoadStmt stmt, ConnectContext context) {
ErrorReport.wrapWithRuntimeException(() -> {
EtlJobType jobType = stmt.getEtlJobType();
if (jobType == EtlJobType.UNKNOWN) {
throw new DdlException(“Unknown load job type”);
}
if (jobType == EtlJobType.HADOOP && Config.disable_hadoop_load) {
throw new DdlException(“Load job by hadoop cluster is disabled.”
+ " Try using broker load. See 'help broker load;'");
}
// 这里进行真正的创建load任务的分析过程
context.getGlobalStateMgr().getLoadManager().createLoadJobFromStmt(stmt, context);
});
return null;
}1
2
3#### 创建load处理pending阶段
+ LoadManager.java -> createLoadJobFromStmt
public void createLoadJobFromStmt(LoadStmt stmt) throws DdlException {
// 校验库元数据
Database database = checkDb(stmt.getLabel().getDbName());
long dbId = database.getId();
LoadJob loadJob = null;
// 加写锁,防止并发
writeLock();
try {
// 校验lable是否已使用
checkLabelUsed(dbId, stmt.getLabel().getLabelName());
if (stmt.getBrokerDesc() == null && stmt.getResourceDesc() == null) {
throw new DdlException(“LoadManager only support the broker and spark load.”);
}
// 判断queue队列长度是否超过1024,超过就报错
if (loadJobScheduler.isQueueFull()) {
throw new DdlException(
“There are more than “ + Config.desired_max_waiting_jobs + “ load jobs in waiting queue, “
+ "please retry later.");
}
// 按load类型初始化出LoadJob
loadJob = BulkLoadJob.fromLoadStmt(stmt);
// 在内存中记录该load元数据
createLoadJob(loadJob);
} finally {
writeUnlock();
}
// 通知bdbje加入load元数据同步
Catalog.getCurrentCatalog().getEditLog().logCreateLoadJob(loadJob);
// loadJob守护进程从load job schedule queue取出任务去执行
loadJobScheduler.submitJob(loadJob);
}1
2
3
4
5
6
7
通过 `createLoadJobFromStmt` 创建load任务
+ LoadJobScheduler.java -> process
注意:LoadJobScheduler 继承自 MasterDaemon,MasterDaemon 继承自 Daemon,
Daemon继承自Thread,重载了run方法,里面有一个loop,主要执行runOneCycle
MasterDaemon 又重写了 runOneCycle,执行 runAfterCatalogReady 函数
LoadJobScheduler 又重写了 runAfterCatalogReady 主要就是干process处理,里面是一个死循环,不断从LinkedBlockingQueue类型的needScheduleJobs里出栈取要执行的job
while (true) {
// take one load job from queue
LoadJob loadJob = needScheduleJobs.poll();
if (loadJob == null) {
return;
}
// schedule job
try {
loadJob.execute();
}1
2
+ LoadJob.java -> execute
public void execute() throws LabelAlreadyUsedException, BeginTransactionException, AnalysisException,
DuplicatedRequestException, LoadException {
// 加写锁,这里防止多并发提交
writeLock();
try {
unprotectedExecute();
} finally {
writeUnlock();
}
}
// 这里主要关注beginTxn,做了事务处理,目的是防止fe节点突然挂掉再拉起后其他follower节点切换到leader节点时会重新执行这个任务,而这个时候旧leader节点已经执行过一段这个任务,导致fe节点之间执行无法同步,所以直接抛出label已经存在不再继续执行
public void unprotectedExecute() throws LabelAlreadyUsedException, BeginTransactionException, AnalysisException,
DuplicatedRequestException, LoadException {
// check if job state is pending
if (state != JobState.PENDING) {
return;
}
// the limit of job will be restrict when begin txn
beginTxn();
unprotectedExecuteJob();
// update spark load job state from PENDING to ETL when pending task is finished
if (jobType != EtlJobType.SPARK) {
unprotectedUpdateState(JobState.LOADING);
}
}1
2
+ SparkLoadJob.java -> unprotectedExecuteJob
protected void unprotectedExecuteJob() throws LoadException {
// create pending task
LoadTask task = new SparkLoadPendingTask(this, fileGroupAggInfo.getAggKeyToFileGroups(),
sparkResource, brokerDesc);
task.init();
idToTasks.put(task.getSignature(), task);
// 注意这里的线程池,初始化时只有5个核心线程(最大线程数),而队列长度只有1024,这里会影响任务长期处于pending状态,如果当前5个任务在下面的spark driver阶段一直等不到yarn资源,则一直处于这个线程执行状态,其他提交进来的任务执行在queue队列中等待
submitTask(Catalog.getCurrentCatalog().getPendingLoadTaskScheduler(), task);
……….
// this.pendingLoadTaskScheduler = new LeaderTaskExecutor(“pending_load_task_scheduler”, Config.max_broker_load_job_concurrency,Config.desired_max_waiting_jobs, !isCheckpointCatalog);
}1
2
3
+ SparkLoadPendingTask.java -> init
// 初始化任务的配置参数
public void init() throws LoadException {
createEtlJobConf();
}1
2
3
+ LoadTask -> exec
// 由于SparkLoadTask继承自LoadTask,而LoadTask实现了PriorityRunnable接口,所以上面的submitTask实际上就是自动执行这里的exec方法
@Override
protected void exec() {
boolean isFinished = false;
try {
// execute pending task
executeTask();
// callback on pending task finished
callback.onTaskFinished(attachment);
isFinished = true;
………
}1
2
3
4
#### load任务处理etl阶段
+ SparkLoadPendingTask.java -> executeTask
void executeTask() throws LoadException {
LOG.info(“begin to execute spark pending task. load job id: {}”, loadJobId);
submitEtlJob();
}1
2
+ SparkLoadPendingTask.java -> submitEtlJob
private void submitEtlJob() throws LoadException {
SparkPendingTaskAttachment sparkAttachment = (SparkPendingTaskAttachment) attachment;
// 配置etl阶段清洗出的文件在hdfs上的存放路径
etlJobConfig.outputPath = EtlJobConfig.getOutputPath(resource.getWorkingDir(), dbId, loadLabel, signature);
sparkAttachment.setOutputPath(etlJobConfig.outputPath);
// 提交etl任务
SparkEtlJobHandler handler = new SparkEtlJobHandler();
handler.submitEtlJob(loadJobId, loadLabel, etlJobConfig, resource, brokerDesc, sparkLoadAppHandle,
sparkAttachment);
LOG.info("submit spark etl job success. load job id: {}, attachment: {}", loadJobId, sparkAttachment);
}1
2
+ SparkEtlJobHandler.java -> submitEtlJob
public void submitEtlJob(long loadJobId, String loadLabel, EtlJobConfig etlJobConfig, SparkResource resource,
BrokerDesc brokerDesc, SparkLoadAppHandle handle, SparkPendingTaskAttachment attachment)
throws LoadException {
// delete outputPath
// init local dir
// prepare dpp archive
SparkLauncher launcher = new SparkLauncher(envs);
// master | deployMode
// ——————|——————-
// yarn | cluster
// spark://xx | client
launcher.setMaster(resource.getMaster())
.setDeployMode(resource.getDeployMode().name().toLowerCase())
.setAppResource(appResourceHdfsPath)
.setMainClass(SparkEtlJob.class.getCanonicalName())
.setAppName(String.format(ETL_JOB_NAME, loadLabel))
.setSparkHome(sparkHome)
.addAppArgs(jobConfigHdfsPath)
.redirectError();
// spark configs
// start app
State state = null;
String appId = null;
String logPath = null;
String errMsg = “start spark app failed. error: “;
try {
// 提交spark任务给yarn
Process process = launcher.launch();
handle.setProcess(process);
if (!FeConstants.runningUnitTest) {
// 监听spark driver输出的日志,直到任务被yarn接收后,退出driver进程
SparkLauncherMonitor.LogMonitor logMonitor = SparkLauncherMonitor.createLogMonitor(handle);
logMonitor.setSubmitTimeoutMs(GET_APPID_TIMEOUT_MS);
logMonitor.setRedirectLogPath(logFilePath);
logMonitor.start();
try {
logMonitor.join();
} catch (InterruptedException e) {
logMonitor.interrupt();
throw new LoadException(errMsg + e.getMessage());
}
}
appId = handle.getAppId();
state = handle.getState();
logPath = handle.getLogPath();
} catch (IOException e) {
LOG.warn(errMsg, e);
throw new LoadException(errMsg + e.getMessage());
}
……….
// success
attachment.setAppId(appId);
attachment.setHandle(handle);
}1
2
3
4
#### load任务处理loading阶段
+ 1、spark load 有一个 LoadEtlChecker定时调度任务,每5s执行一次
protected void runAfterCatalogReady() {
try {
loadManager.processEtlStateJobs();
} catch (Throwable e) {
LOG.warn(“Failed to process one round of LoadEtlChecker with error message {}”, e.getMessage(), e);
}
}1
2
+ 2、这个定时调度就是定时检查load任务状态,有变化就去更新,简单说就是load状态扭转控制器
// only for those jobs which have etl state, like SparkLoadJob
public void processEtlStateJobs() {
idToLoadJob.values().stream().filter(job -> (job.jobType == EtlJobType.SPARK && job.state == JobState.ETL))
.forEach(job -> {
try {
((SparkLoadJob) job).updateEtlStatus();
} catch (DataQualityException e) {
LOG.info(“update load job etl status failed. job id: {}”, job.getId(), e);
job.cancelJobWithoutCheck(new FailMsg(FailMsg.CancelType.ETL_QUALITY_UNSATISFIED,
DataQualityException.QUALITY_FAIL_MSG),
true, true);
} catch (TimeoutException e) {
// timeout, retry next time
LOG.warn(“update load job etl status failed. job id: {}”, job.getId(), e);
} catch (UserException e) {
LOG.warn(“update load job etl status failed. job id: {}”, job.getId(), e);
job.cancelJobWithoutCheck(new FailMsg(CancelType.ETL_RUN_FAIL, e.getMessage()), true, true);
} catch (Exception e) {
LOG.warn(“update load job etl status failed. job id: {}”, job.getId(), e);
}
});
}1
2
+ 3、当任务状态走到loading时,会提交load任务,函数是submitPushTasks(),这里简单说就是把表的排序健/分区/be副本等查询出来,后面要把这些元数据通过rpc调用be来处理
if (tablet instanceof LocalTablet) {
for (Replica replica : ((LocalTablet) tablet).getImmutableReplicas()) {
long replicaId = replica.getId();
tabletAllReplicas.add(replicaId);
long backendId = replica.getBackendId();
Backend backend = GlobalStateMgr.getCurrentState().getCurrentSystemInfo()
.getBackend(backendId);
pushTask(backendId, tableId, partitionId, indexId, tabletId,
replicaId, schemaHash, params, batchTask, tabletMetaStr,
backend, replica, tabletFinishedReplicas, TTabletType.TABLET_TYPE_DISK);
}
if (tabletAllReplicas.size() == 0) {
LOG.error("invalid situation. tablet is empty. id: {}", tabletId);
}
// check tablet push states
if (tabletFinishedReplicas.size() >= quorumReplicaNum) {
quorumTablets.add(tabletId);
if (tabletFinishedReplicas.size() == tabletAllReplicas.size()) {
fullTablets.add(tabletId);
}
}
}1
2
+ 4、遍历生成出的每个tablet,再去遍历每个副本replica,都会给每个replica提交一个load任务,那这里要注意的是会构造
PushTask pushTask = new PushTask(backendId, dbId, tableId, partitionId,
indexId, tabletId, replicaId, schemaHash,
0, id, TPushType.LOAD_V2,
TPriority.NORMAL, transactionId, taskSignature,
tBrokerScanRange, params.tDescriptorTable,
params.useVectorized, timezone, tabletType);
if (AgentTaskQueue.addTask(pushTask)) {
batchTask.addTask(pushTask);
if (!tabletToSentReplicaPushTask.containsKey(tabletId)) {
tabletToSentReplicaPushTask.put(tabletId, Maps.newHashMap());
}
tabletToSentReplicaPushTask.get(tabletId).put(replicaId, pushTask);
}1
2
+ 5、会通过thrift rpc 通知这个副本的be,主要是这个地方client.submit_tasks(agentTaskRequests);
// create AgentClient
address = new TNetworkAddress(backend.getHost(), backend.getBePort());
client = ClientPool.backendPool.borrowObject(address);
List
for (AgentTask task : tasks) {
agentTaskRequests.add(toAgentTaskRequest(task));
}
client.submit_tasks(agentTaskRequests);1
2
+ 6、这个submit_tasks方法主要是调用BackendService类,这个类实现在be这一侧
public com.starrocks.thrift.TAgentResult submit_tasks(java.util.List
{
send_submit_tasks(tasks);
return recv_submit_tasks();
}1
2
3
4
5
6
7
8
9
10
11这个submit_tasks方法是 Thrift 生成的 Java 客户端代码。它和 C++ 服务端的对应关系是:
1) fe发送 Thrift RPC 请求,调用这个 Java submit_tasks方法。
2) Thrift框架会将参数 tasks 序列化成数据包,发送给服务端be。
3) be服务端 Thrift 接收到数据包,反序列化出 tasks 参数。
4) 根据方法名submit_tasks映射到 C++ 的 BackendService::submit_tasks 方法,将 tasks 作为参数调用它。
5) C++ 方法执行完成,将返回值通过 Thrift 序列化后发送给客户端。
6) Java 端 recv_submit_tasks 反序列化出返回结果,赋值给 submit_tasks 方法的返回值。
7) submit_tasks 返回结果,Java 前端获得调用结果。
#### be部分如何处理loading的代码逻辑
+ 1、BackendService的rpc服务在启动be时已开启
// Begin to start services
// 1. Start thrift server with ‘be_port’.
auto thrift_server = BackendService::create
if (auto status = thrift_server->start(); !status.ok()) {
LOG(ERROR) << “Fail to start BackendService thrift server on port “ << starrocks::config::be_port << “: “
<< status;
starrocks::shutdown_logging();
exit(1);
}1
2
3
+ 2、客户端BackendServiceClient::submit_tasks()会序列化tasks参数,然后发送RPC请求到服务端,服务端的RPC框架收到请求,根据方法名映射到BackendService::submit_tasks()
void BackendService::submit_tasks(TAgentResult& return_value, const std::vector
_agent_server->submit_tasks(return_value, tasks);
}1
2
3
+ 3、而agent_server里处理submit_tasks的核心逻辑是再次调用PushTaskWorkerPool下的submit_tasks
// batch submit push tasks
if (!push_divider.empty()) {
LOG(INFO) << “begin batch submit task: “ << tasks[0].task_type;
for (const auto& push_item : push_divider) {
const auto& push_type = push_item.first;
auto all_push_tasks = push_item.second;
switch (push_type) {
case TPushType::LOAD_V2:
_push_workers->submit_tasks(all_push_tasks);
break;
case TPushType::DELETE:
case TPushType::CANCEL_DELETE:
_delete_workers->submit_tasks(all_push_tasks);
break;
default:
ret_st = Status::InvalidArgument(strings::Substitute(“tasks(type=$0, push_type=$1) has wrong task type”,
TTaskType::PUSH, push_type));
LOG(WARNING) << “fail to batch submit push task. reason: “ << ret_st.get_error_msg();
}
}
}1
2
+ 4、在TaskWorkPool里处理submit_tasks的,主要是实现批量注册task信息,做去重和幂等校验,成功后进行遍历,核心函数是_convert_task
for (size_t i = 0; i < task_count; i++) {
if (failed_task[i] == 0) {
auto new_task = _convert_task(*tasks[i], recv_time);
_tasks.emplace_back(std::move(new_task));
}
}1
2
+ 5、_convert_task它会将TAgentTaskRequest转换成PushReqAgentTaskRequest类型的任务请求,这个是通用线程池,构造函数里回调了_worker_thread_callback,构造出的EngineBatchLoadTask对象后取执行task
EngineBatchLoadTask engine_task(push_req, &tablet_infos, agent_task_req->signature, &status,
ExecEnv::GetInstance()->load_mem_tracker());
StorageEngine::instance()->execute_task(&engine_task);1
2
+ 6、在EngineBatchLoadTask::execute()里追踪了内存使用后,会检查tablet是否存在,目录是否达到存储限制等,继续执行load_v2(sparkload/brokerload)的_process,而_process也是做了下校验后提交到_push里
if (status == STARROCKS_SUCCESS) {
uint32_t retry_time = 0;
while (retry_time < PUSH_MAX_RETRY) {
status = _process();
if (status == STARROCKS_PUSH_HAD_LOADED) {
LOG(WARNING) << "transaction exists when realtime push, "
"but unfinished, do not report to fe, signature: "
<< _signature;
break; // not retry anymore
}
// Internal error, need retry
if (status == STARROCKS_ERROR) {
LOG(WARNING) << "push internal error, need retry.signature: " << _signature;
retry_time += 1;
} else {
break;
}
}
}1
2
+ 7、在_push()里初始化了PushHandler类,现在才开始处理数据的摄入过程
vectorized::PushHandler push_handler;
res = push_handler.process_streaming_ingestion(tablet, request, type, tablet_info_vec);1
2
+ 8、在核心逻辑_do_streaming_ingestion函数里,开始检查这个tablet是否能迁移,能的话,拿回tablet的写锁后做load转换过程
Status st = Status::OK();
if (push_type == PUSH_NORMAL_V2) {
st = _load_convert(tablet_vars->at(0).tablet, &(tablet_vars->at(0).rowset_to_add));
}1
2
+ 9、而在_load_convert里就是初始化出RowsetWriterContext这个上下文对象和RowsetWriter,RowsetWriter对象主要是需要去读出tablet的每一行,用这个wirter写回
st = reader->init(t_scan_range, _request);
if (!st.ok()) {
LOG(WARNING) << “fail to init reader. res=” << st.to_string() << “, tablet=” << cur_tablet->full_name();
return st;
}1
2
+ 10、而reader的初始化就是构造PushBrokerReader对象,在PushBrokerReader里会按照文件类型构造出扫描对象,们目前通过sparkload处理的数据,都是使用parquet格式,所以这个初始化就是初始化出ParquetScanner
// init scanner
FileScanner* scanner = nullptr;
switch (t_scan_range.ranges[0].format_type) {
case TFileFormatType::FORMAT_PARQUET: {
scanner = new ParquetScanner(_runtime_state.get(), _runtime_profile, t_scan_range, _counter.get());
if (scanner == nullptr) {
return Status::InternalError(“Failed to create scanner”);
}
break;
}1
2
+ 11、再回到PushHandler里的_load_conver函数的读取tablet过程,也是按行来去读一个个chunk,而这个next_chunk在PushBrokerReader里又是如何处理的呢?
ChunkPtr chunk = ChunkHelper::new_chunk(schema, 0);
while (!reader->eof()) {
st = reader->next_chunk(&chunk);
if (!st.ok()) {
LOG(WARNING) << “fail to read next chunk. err=” << st.to_string() << “, read_rows=” << num_rows;
return st;
} else {
if (reader->eof()) {
break;
}
st = rowset_writer->add_chunk(*chunk);
if (!st.ok()) {
LOG(WARNING) << "fail to add chunk to rowset writer"
<< ". res=" << st << ", tablet=" << cur_tablet->full_name()
<< ", read_rows=" << num_rows;
return st;
}
num_rows += chunk->num_rows();
chunk->reset();
}
}1
2
+ 12、next_chunk函数会通过scanner对象,去读每行,直到读完为止,再把读出来的结果转换成chunk
auto res = _scanner->get_next();
if (res.status().is_end_of_file()) {
_eof = true;
return Status::OK();
} else if (!res.ok()) {
return res.status();
}
return _convert_chunk(res.value(), chunk);1
2
+ 13、在parquet_scanner里是如何读每个行的呢?当然是按批来读,把读出的批追加到chunk去,chunk满了就返回,这种方式就是通用的流式数据处理,避免了一次新把整个parquet读到内存里,在这里主要关注到next_batch函数,就是Parquet文件的读取流程
const TBrokerRangeDesc& range_desc = _scan_range.ranges[_next_file];
Status st = create_random_access_file(range_desc, _scan_range.broker_addresses[0], _scan_range.params,
CompressionTypePB::NO_COMPRESSION, &file);
14、而在create_random_access_file函数由于parquet_scanner是继承自file_scanner,统一回来按文件类型去创建RandomAccessFile的逻辑
int64_t timeout_ms = _state->query_options().query_timeout * 1000 / 4;
timeout_ms = std::max(timeout_ms, static_cast
BrokerFileSystem fs_broker(address, params.properties, timeout_ms);
if (config::use_local_filecache_for_broker_random_access_file) {
ASSIGN_OR_RETURN(auto broker_file, fs_broker.new_sequential_file(range_desc.path));
std::string dest_path = create_tmp_file_path();
LOG(INFO) << "broker load cache file: " << dest_path;
ASSIGN_OR_RETURN(auto dest_file, FileSystem::Default()->new_writable_file(dest_path));
auto res = fs::copy(broker_file.get(), dest_file.get(), 10 * 1024 * 1024);
std::shared_ptr<RandomAccessFile> local_file;
ASSIGN_OR_RETURN(local_file, FileSystem::Default()->new_random_access_file(dest_path));
src_file = std::make_shared<TempRandomAccessFile>(dest_path, local_file);
}1
2
+ 15、使用BrokerFileSystem通过broker来打开文件(这里的address就是我们在fe节点里创建tBrokerScanRange传入的),用broker把hdfs上的文件下载到本地临时目录下,再打开本地临时目录
Status st = call_method(_broker_addr, &BrokerServiceClient::openReader, request, &response);
if (!st.ok()) {
LOG(WARNING) << “Fail to open “ << path << “: “ << st;
return st;
}
if (response.opStatus.statusCode != TBrokerOperationStatusCode::OK) {
LOG(WARNING) << “Fail to open “ << path << “: “ << response.opStatus.message;
return to_status(response.opStatus);
}
// Get file size.
ASSIGN_OR_RETURN(const uint64_t file_size, get_file_size(path));
auto stream = std::make_shared
return std::make_unique1
2
3
4
注意,这里又是通过rpc来调用broker了
+ 16、再回来看parquet_scanner里的get_next()函数,就是整个parquet文件的核心逻辑,而核心里的调用就是初始化chunk的逻辑
Status ParquetScanner::initialize_src_chunk(ChunkPtr chunk) {
SCOPED_RAW_TIMER(&_counter->init_chunk_ns);
_pool.clear();
(chunk) = std::make_shared
size_t column_pos = 0;
_chunk_filter.clear();
for (auto i = 0; i < _num_of_columns_from_file; ++i) {
SlotDescriptor slot_desc = _src_slot_descriptors[i];
if (slot_desc == nullptr) {
continue;
}
auto array = _batch->column(column_pos++).get();
ColumnPtr column;
RETURN_IF_ERROR(new_column(array->type().get(), slot_desc, &column, &_conv_funcs[i], &_cast_exprs[i]));
column->reserve(_max_chunk_size);
(*chunk)->append_column(column, slot_desc->id());
}
return Status::OK();
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
251) 清空内存池
2) 创建新的空chunk
3) 遍历所有columns:
3.1、如果column在schema中,获取对应的SlotDescriptor
3.2、根据数组类型和SlotDescriptor创建新的Column
3.3、预留chunk大小内存
3.4、将Column添加到chunk
4) 返回OK状态
这样就构造了一个空的、符合schema的chunk。
主要逻辑是:
- 清理内存池重用
- 创建空chunk
- 为每个column创建对应的Column对象
- 预留内存
- 添加到chunk
这是非常标准的按schema构建chunk的过程。
这种实现可以高效构建chunk,同时预留内存减少后续内存分配,并可以重用内存池避免频繁new/delete。
构建一个符合schema并预分配内存的空chunk是vectorized执行的基础,这个初始化实现是非常重要的一步
### 演进之路
> 上面主要解读了整个离线导入过程的核心代码,在离线导入模块集成到同步中心后,也遇到了一些问题,进行了3次升级来支持不同业务侧对离线导入的需求,下面主要介绍下几个大feature的升级
#### 国际化业务需要字符串分区
滴滴内部的国际化业务,由于不同国家有时区问题,所以业务侧在hive建表时总会创建出dt=yyyy-mm-dd/country_code=xx的表结构,但如果要将这种hive表结构导入到sr,在当前官方版本都是不支持的,一直到3.0+版本我们和社区一起共建了string类型分区这个feature,并且在离线导入这一块进行了深度迭代升级,用以支撑国际化业务的快速落地sr,这个feature我们已经和入到官方版本中,当前社区版本需要在3.0+才可以支持string类型分区,而滴滴内部在2.3和2.5都已经支持了string类型分区功能,如下表结构
CREATE TABLE db.tb (
is_passenger varchar(65533),
country_code varchar(65533),
dt varchar(65533),
pid varchar(65533),
resource_stage_1_show_cnt bigint(20)
) ENGINE=OLAP
DUPLICATE KEY(is_passenger, country_code, dt)
COMMENT “xxxx”
PARTITION BY LIST(country_code,dt)(
PARTITION pMX_20231208 VALUES IN ((‘MX’, ‘2023-12-08’))
)
DISTRIBUTED BY HASH(pid) BUCKETS 48
PROPERTIES (
“replication_num” = “3”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”,
“enable_persistent_index” = “false”
);1
2
3
#### spark任务提交由于yarn资源缺乏只能等待5分钟便终止等待load退出
滴滴内部yarn资源队列core和memory均做了一定限制,在降本增效的前提下,很多业务侧无法再去扩容yarn队列,而sr官方社区版本在spark任务提交给yarn之后,默认只给等待5分钟,如果始终等不到yarn接收任务,则自动退出,针对这种特定场景,我们优化了load任务的执行流程,引入了`"spark_load_submit_timeout" = "7200"`参数,在每个load任务提交后都可以自动化配置这个任务需要等待yarn多少时间,并且如果spark任务确实等待超时后无法提交,也加入了通知yarn去杀死这个等待的spark任务,防止后续等待到yarn资源后又再次提交执行,而sr这一侧load已经退出,白白浪费资源,如下load结构
LOAD LABEL db.lable_name_xxx (
DATA INFILE(
“hdfs://DClusterUS1/xxxxx”
)
INTO TABLE tb
TEMPORARY PARTITION(temppartition)
FORMAT AS “ORC”
(column_1, column_2)
SET (
column_1 = if(column_1 is null or column_1 = “null”, null, column_1),
column_2 = if(column_2 is null or column_2 = “null”, null, column_2),
dt = “2023-12-09”,
country_code = “MX”
)
) WITH RESOURCE ‘external_spark_resource’ (
“spark.yarn.tags” = “xxxxxxx”,
“spark.dynamicAllocation.enabled” = “true”,
“spark.executor.memory” = “3g”,
“spark.executor.memoryOverhead” = “2g”,
“spark.streaming.batchDuration” = “5”,
“spark.executor.cores” = “1”,
“spark.yarn.executor.memoryOverhead” = “2g”,
“spark.speculation” = “false”,
“spark.dynamicAllocation.minExecutors” = “2”,
“spark.dynamicAllocation.maxExecutors” = “100”
) PROPERTIES (
“timeout” = “36000”,
“spark_load_submit_timeout” = “7200”
)1
2
3
4
5
6
7
#### 由于spark driver进程在fe节点中占用过多内存,会导致cgroup自动杀死fe进程
目前我们的k8s集群对fe节点的配置只有12g,所以大批量spark driver进程在fe节点中,按照之前统计每个dirver进程大约会占用200-300mb,而fe进程的元数据占用内存大约在5g-10g之间,所以留给spark driverfe进程的可用内存其实非常少,但是目前大量业务侧使用离线导入功能,这样就会造成fe进程不定时被kill的困局,针对这个场景,我们开发了load限流功能,将并发提交的任务转入限流队列中,由队列资源来控制当前任务的并行度,在fe节点内存资源达到高峰期时,进行相应的限流策略,用以保障fe节点的稳定性,如下所示

#### 由于hivesql写入的hive表产出的hdsf文件自动生成的格式是_col1..._coln,在通过字段导入时会造成hive表字段和sr表字段映射失败
在离线导入功能演进过程中,这个场景在大量业务侧被迫切提出需求,业务侧由于业务口径的变更,需要对hive表进行修改,而一修改hive表结构,历史数据回溯时就会出现分区映射的hdfs文件无法正确映射成功,这个场景和通过hive sql导入hive表时一样的,hive和sr之间字段无法映射成功,就造成导入失败,针对这一场景我们升级了离线导入模块,引入了spark sql模式来读取hive表,而不是之前的spark 文件方式读取,这种方式成功解决了用户变更表字段回溯场景和hive sql导入场景,如下load结构:
LOAD LABEL db.label_name (
DATA FROM TABLE hive_tb
INTO TABLE sr_tb
TEMPORARY PARTITION(temppartition)
SET (column_1 = if(column_1 is null or column_1 = “null”, null, column_1),column_2 = if(column_2 is null or column_2 = “null”, null, column_2),
…….
)
WHERE (dt = ‘2023-12-09’)
)WITH RESOURCE ‘spark_external_resource’ (
“spark.yarn.tags” = “h2s_foit_150748320231209914ff11b87c94c85947ab13f84ff4622”,
“spark.dynamicAllocation.enabled” = “true”,
“spark.executor.memory” = “3g”,
“spark.executor.memoryOverhead” = “2g”,
“spark.streaming.batchDuration” = “5”,
“spark.executor.cores” = “1”,
“spark.yarn.executor.memoryOverhead” = “2g”,
“spark.speculation” = “false”,
“spark.dynamicAllocation.minExecutors” = “2”,
“spark.dynamicAllocation.maxExecutors” = “100”
) PROPERTIES (
“timeout” = “36000”,
“spark_load_submit_timeout” = “7200”
)
```
注意:目前spark sql导入只在明细模型(duplicate key)和聚合模型(aggregate key)上支持
未来规划
目前starrocks离线导入功能已经集成在滴滴的同步中心,用户可以通过同步中心按hive表结构自动创建sr表结构,并且配置出hive表字段和sr表字段的映射关系后,构造出导入配置相应参数,调用sr的离线导入模块进行数据导入,而这个导入功能我们在2024年也会有以下规划:
spark sql支持主键模型(primary key)
目前有一部分业务侧会通过主键模型将hive分区数据定时导回给sr,当前还不支持spark sql方式导入,2024年我们会进行这个feature开发
独立sr构建工具
当前的etl构建过程仍然需要在fe进程中进行交互处理,但fe节点我们在k8s初始化时只有12g,虽然在演进之路里我们加入了限流功能来保障fe稳定性,但是这个方式也会将hive导入耗时加大,对于一些需要高优保障的任务仍然需要按时产出,所以我们规划在2024年可以将这个构建工具从sr的fe进程中独立出来,单独部署在构建集群中,在完成etl阶段后,通过rpc方式通知给sr的fe进程来拉取
hive外表联邦查询
当前很多业务侧的hive表分区压缩后也会在100g+,这种case导入到sr后查询性能也不一定会很好,但是导入过程却很浪费资源,我们计划在2024年完成hive外表的集成功能,让用户可以直接通过sr来查询hive表,而不需要再进行分区导入这一部分操作