链接
TCP标志
SYN: (同步序列编号,Synchronize Sequence Numbers)该标志仅在三次握手建立TCP连接时有效。表示一个新的TCP连接请求。
ACK: (确认编号,Acknowledgement Number)是对TCP请求的确认标志,同时提示对端系统已经成功接收所有数据。
FIN: (结束标志,FINish)用来结束一个TCP回话.但对应端口仍处于开放状态,准备接收后续数据。
TCP状态
TCP状态在系统里都有对应的解释或设置,可见man tcp,以下介绍主要常见的几种
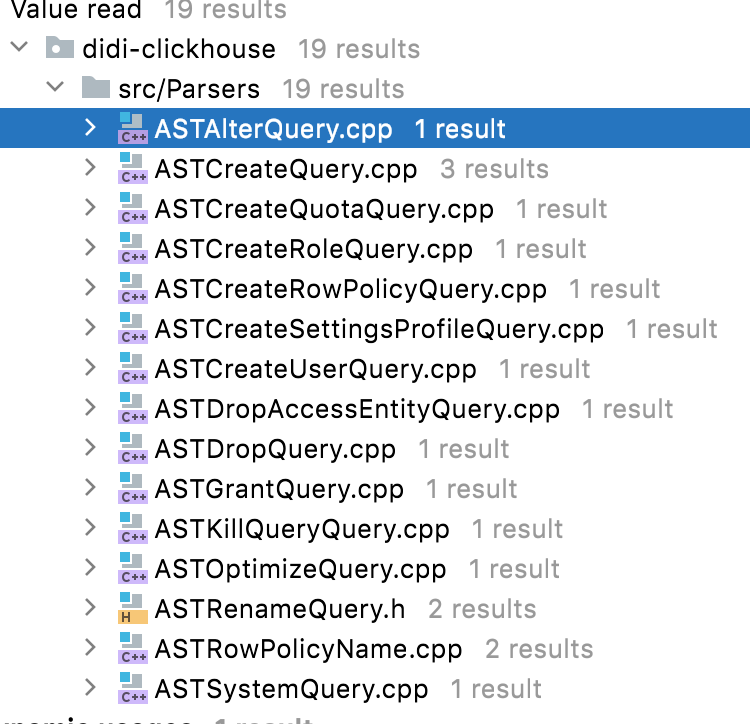
1)、LISTEN: 首先服务端需要打开一个socket进行监听,状态为LISTEN.
/ The socket is listening for incoming connections. 侦听来自远方TCP端口的连接请求 /
2)、SYN_SENT: 客户端通过应用程序调用connect进行active open.于是客户端tcp发送一个SYN以请求建立一个连接.之后状态置为SYN_SENT.
/The socket is actively attempting to establish a connection. 在发送连接请求后等待匹配的连接请求 /
3)、SYN_RECV: 服务端应发出ACK确认客户端的SYN,同时自己向客户端发送一个SYN. 之后状态置为SYN_RECV
/ A connection request has been received from the network. 在收到和发送一个连接请求后等待对连接请求的确认 /
4)、ESTABLISHED: 代表一个打开的连接,双方可以进行或已经在数据交互了。
/ The socket has an established connection. 代表一个打开的连接,数据可以传送给用户 /
5)、FIN_WAIT1:主动关闭(active close)端应用程序调用close,于是其TCP发出FIN请求主动关闭连接,之后进入FIN_WAIT1状态.
/ The socket is closed, and the connection is shutting down. 等待远程TCP的连接中断请求,或先前的连接中断请求的确认 /
6)、CLOSE_WAIT: 被动关闭(passive close)端TCP接到FIN后,就发出ACK以回应FIN请求(它的接收也作为文件结束符传递给上层应用程序),并进入CLOSE_WAIT.
/ The remote end has shut down, waiting for the socket to close. 等待从本地用户发来的连接中断请求 /
7)、FIN_WAIT2: 主动关闭端接到ACK后,就进入了FIN-WAIT-2 .
/ Connection is closed, and the socket is waiting for a shutdown from the remote end. 从远程TCP等待连接中断请求 /
8)、LAST_ACK: 被动关闭端一段时间后,接收到文件结束符的应用程序将调用CLOSE关闭连接。这导致它的TCP也发送一个 FIN,等待对方的ACK.就进入了LAST-ACK .
/ The remote end has shut down, and the socket is closed. Waiting for acknowledgement. 等待原来发向远程TCP的连接中断请求的确认 /
9)、TIME_WAIT: 只发生在主动关闭连接的一方。主动关闭方在接收到被动关闭方的FIN请求后,发送成功给对方一个ACK后,将自己的状态由FIN_WAIT2修改为TIME_WAIT,而必须再等2倍 的MSL(Maximum Segment Lifetime,MSL是一个数据报在internetwork中能存在的时间)时间之后双方才能把状态 都改为CLOSED以关闭连接。目前RHEL里保持TIME_WAIT状态的时间为60秒。
/ The socket is waiting after close to handle packets still in the network.等待足够的时间以确保远程TCP接收到连接中断请求的确认 /
10)、CLOSING: 比较少见.
/ Both sockets are shut down but we still don’t have all our data sent. 等待远程TCP对连接中断的确认 /
11)、CLOSED: 被动关闭端在接受到ACK包后,就进入了closed的状态。连接结束.
/ The socket is not being used. 没有任何连接状态 /
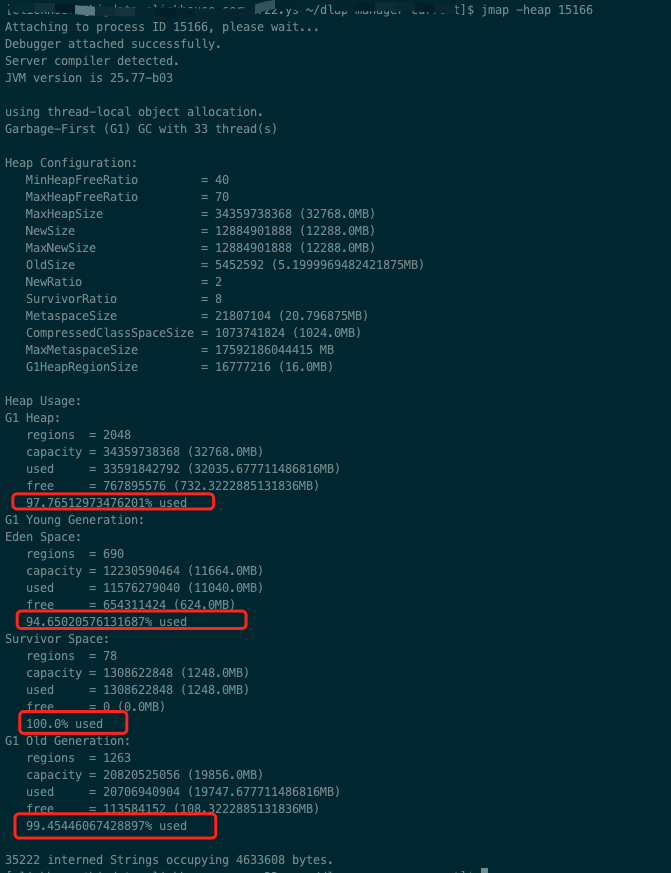
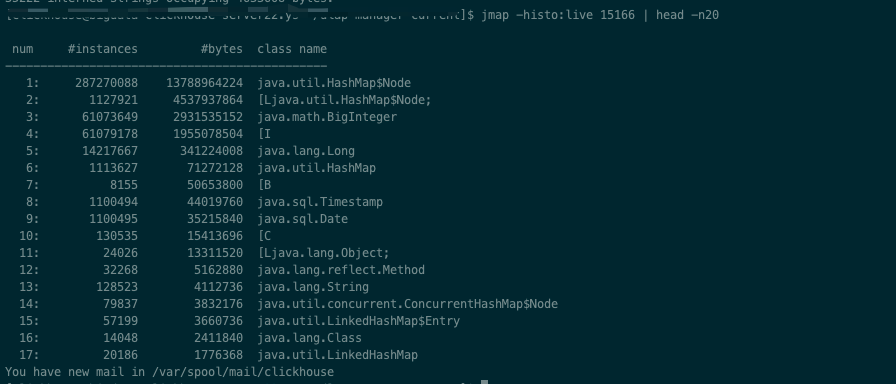
为什么创建的连接需要关闭?
如果不关闭连接,这些系统资源将一直在内存中,等待下一次系统gc时才会被回收,而如果系统频繁的fgc将会导致你的程序明显卡顿,如果一直没有gc,也会导致你的内存泄漏
如果一定要关闭,那是不是可以使用单例模式在所有地方使用?
是不是可以使用连接池,一次创建n个连接,用完归还到池子里等下次再被使用?