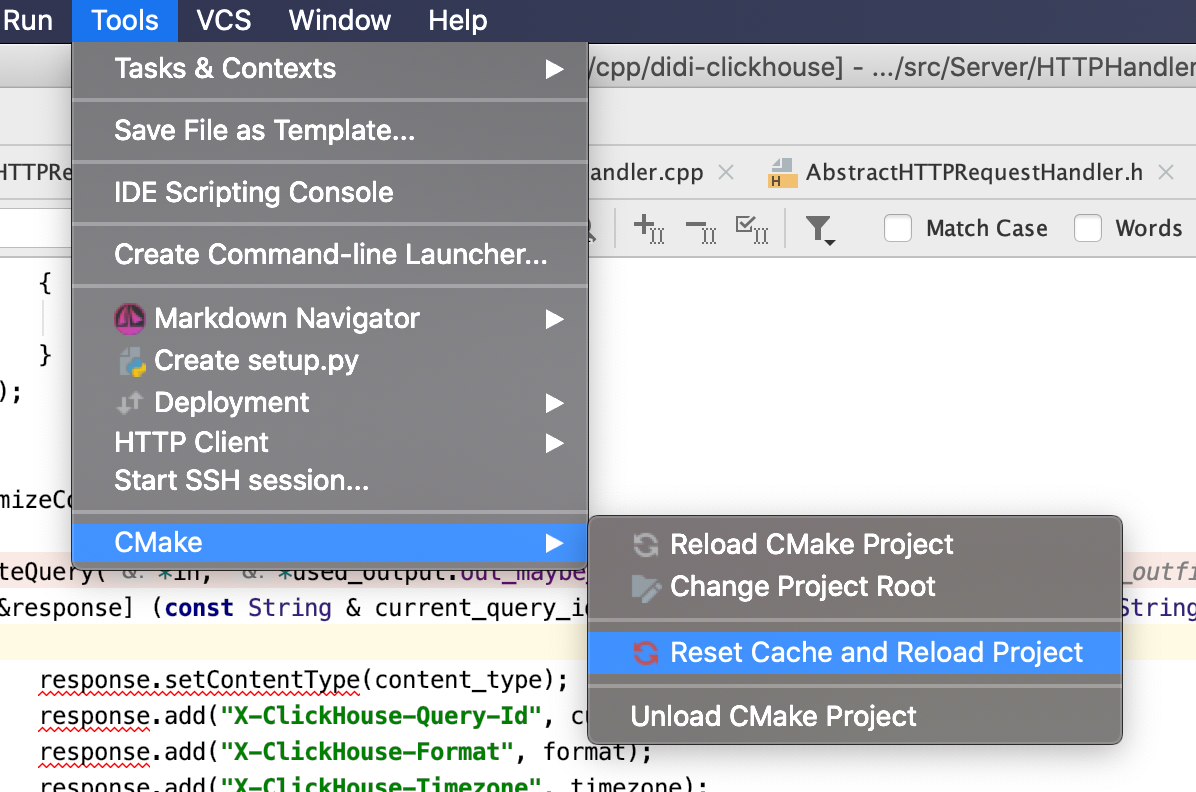
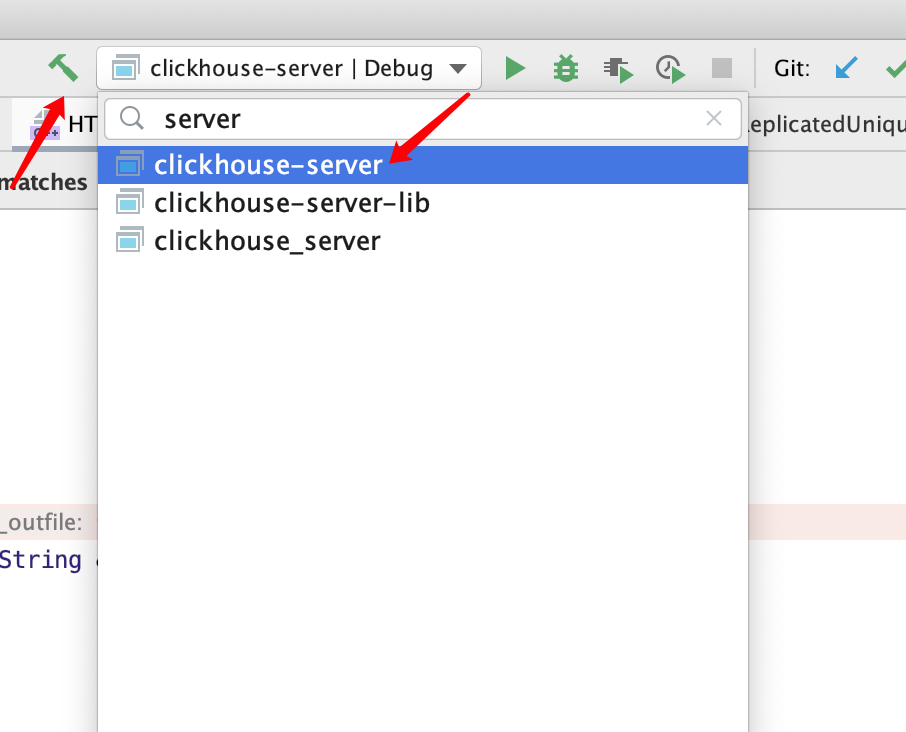
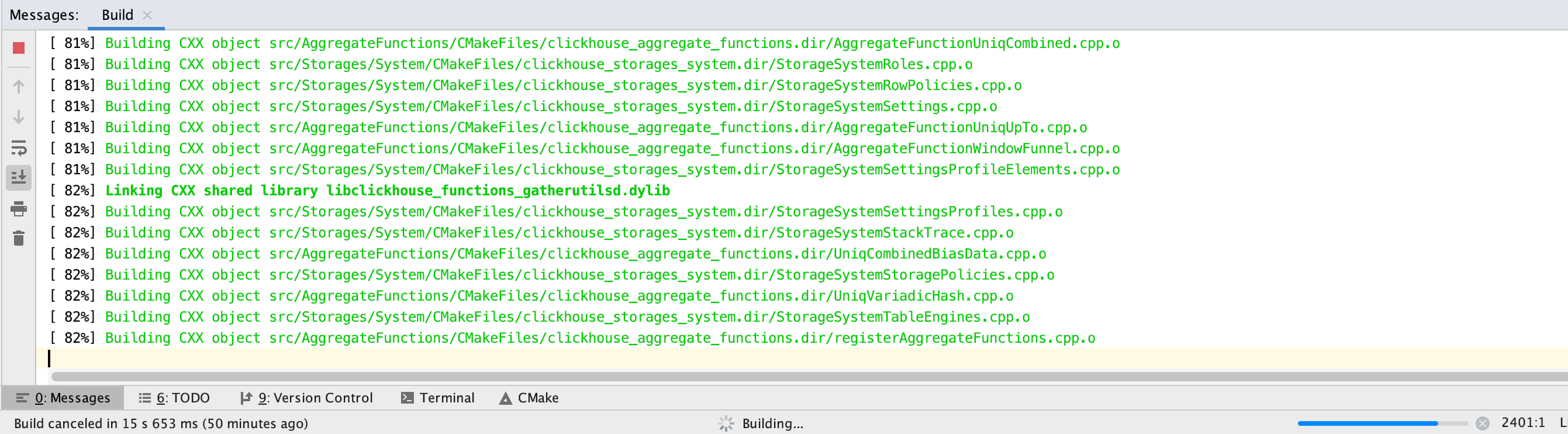
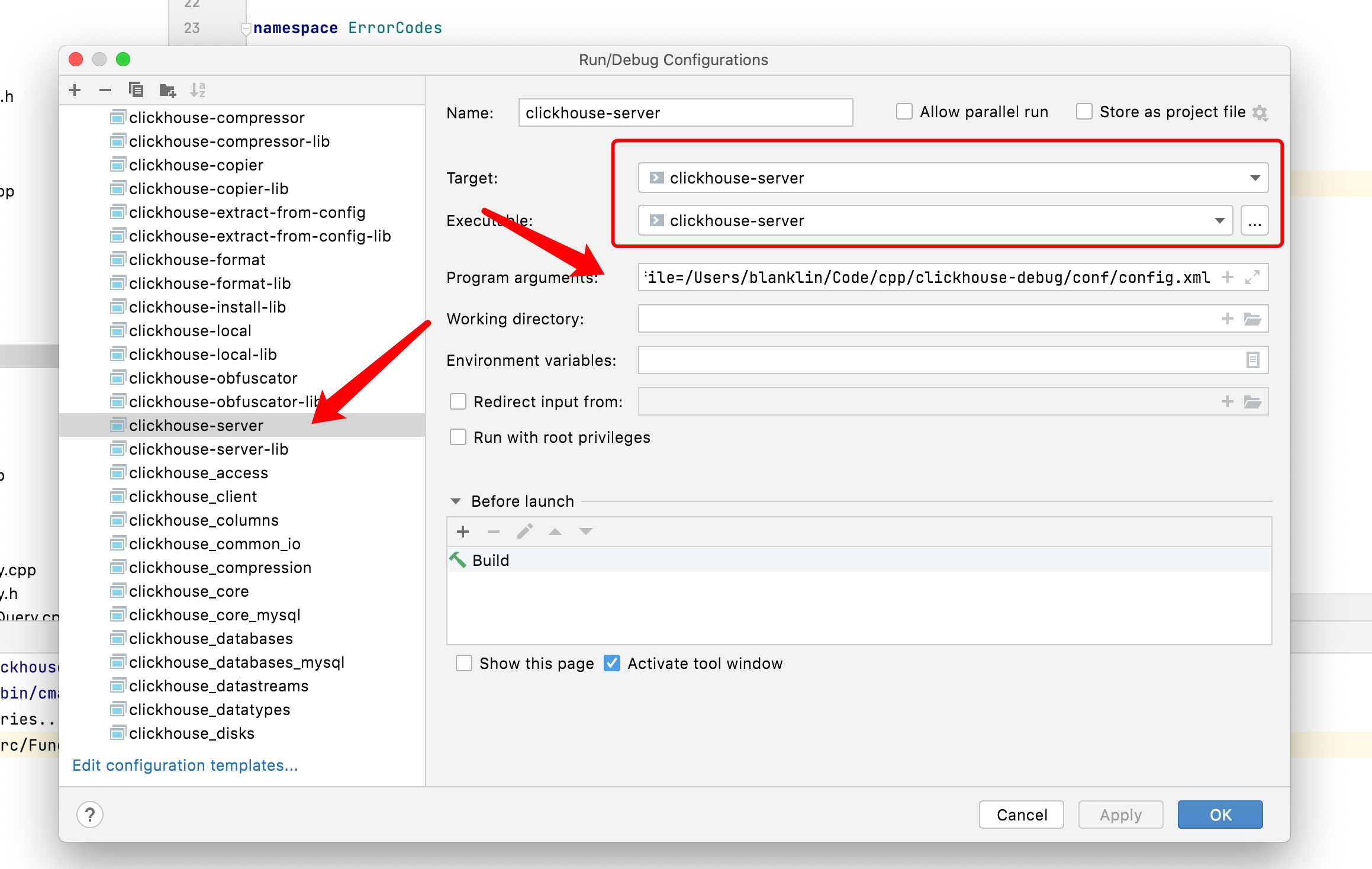
// 简单范型 class Test<T> { private T var; public T getVar() { return var; } public void setVar(T var) { this.var = var; } } // 多元泛型 class TestKV<K,V> { private K key; private V value; public K getKey() { return key; } public void setKey(K key) { this.key = key; } public V getValue() { return value; } public void setValue(V value) { this.value = value; } }
public class Demo { public static void main(String[] args) { Test<String> test = new Test<String>(); test.setVar("aa"); System.out.println(test.getVar());
interface Test<T> { public T getVar(); } class TestImpl<T> implement Test<T> { private T var; public TEstImpl(T var) { this.var = var; } public T getVar() { return var; } public void setVar(T var) { this.var = var; } } public class Demo{ public static void main(String[] args) { Test<String> test = new TestImpl<String>("tom"); System.out.pringln(test.getVar()); } }
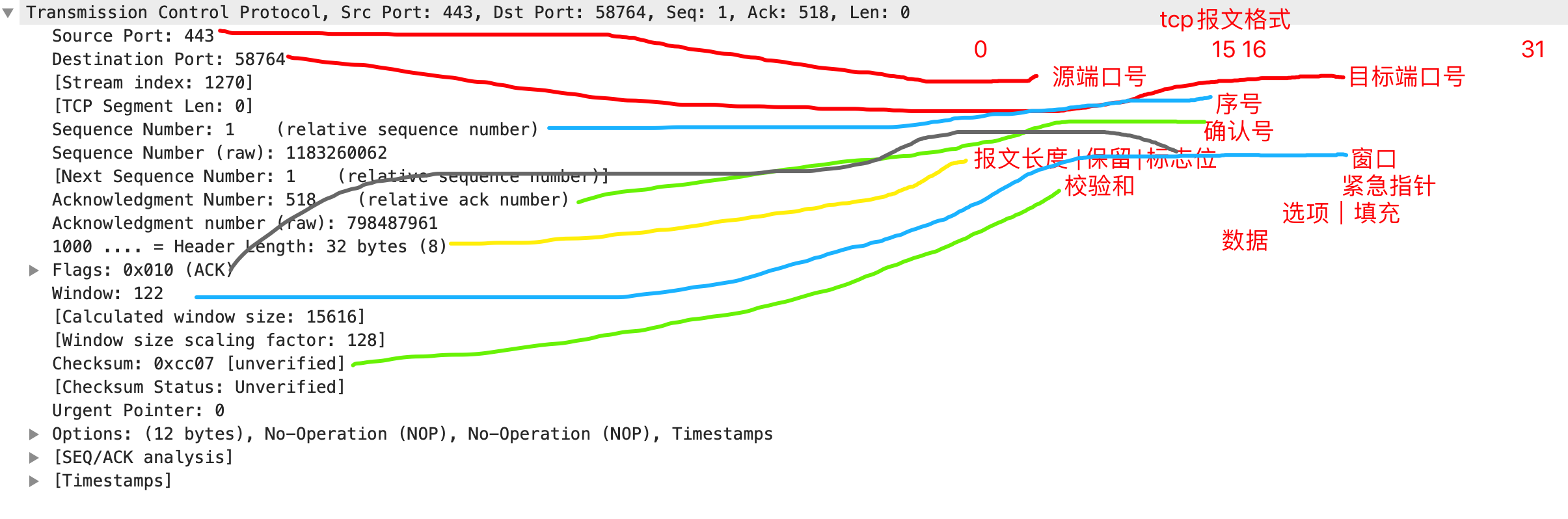
泛型方法
1 2 3 4 5 6
public class Demo { public <T> T getObject(Class<T> c) { T t = c.newInstance(); retrun t; } }
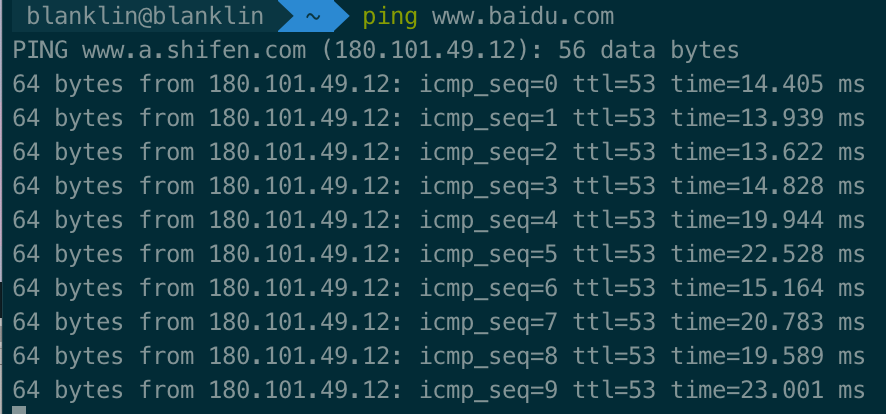
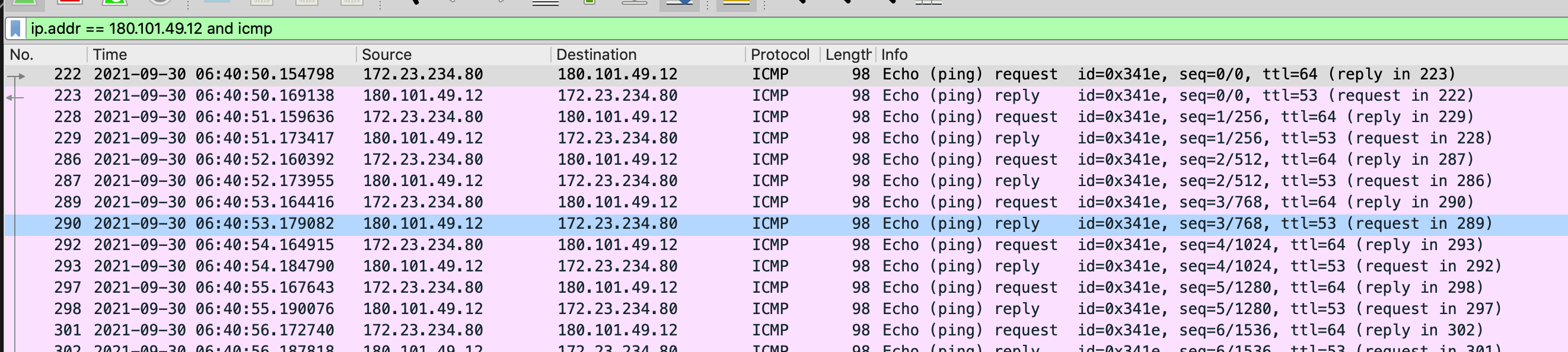
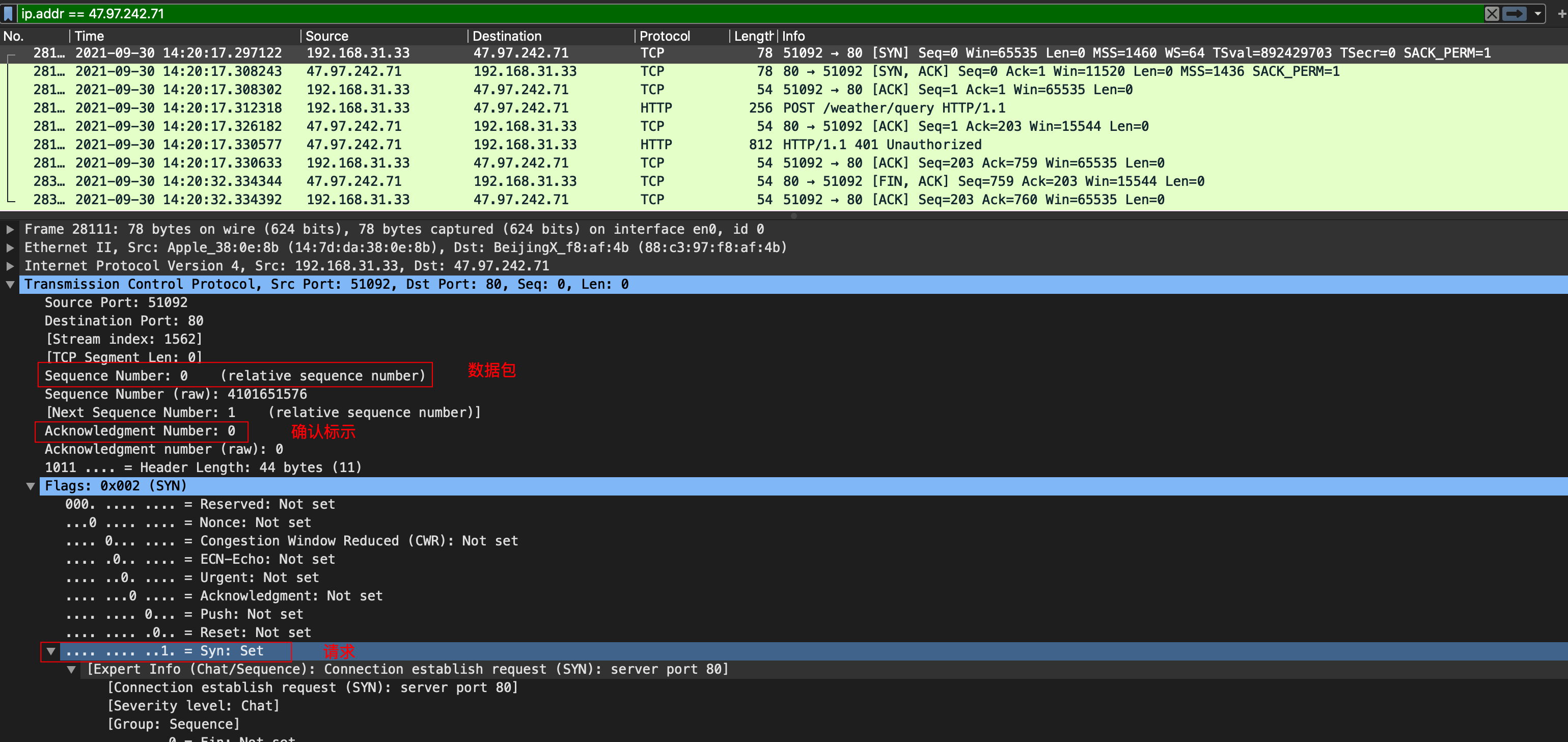
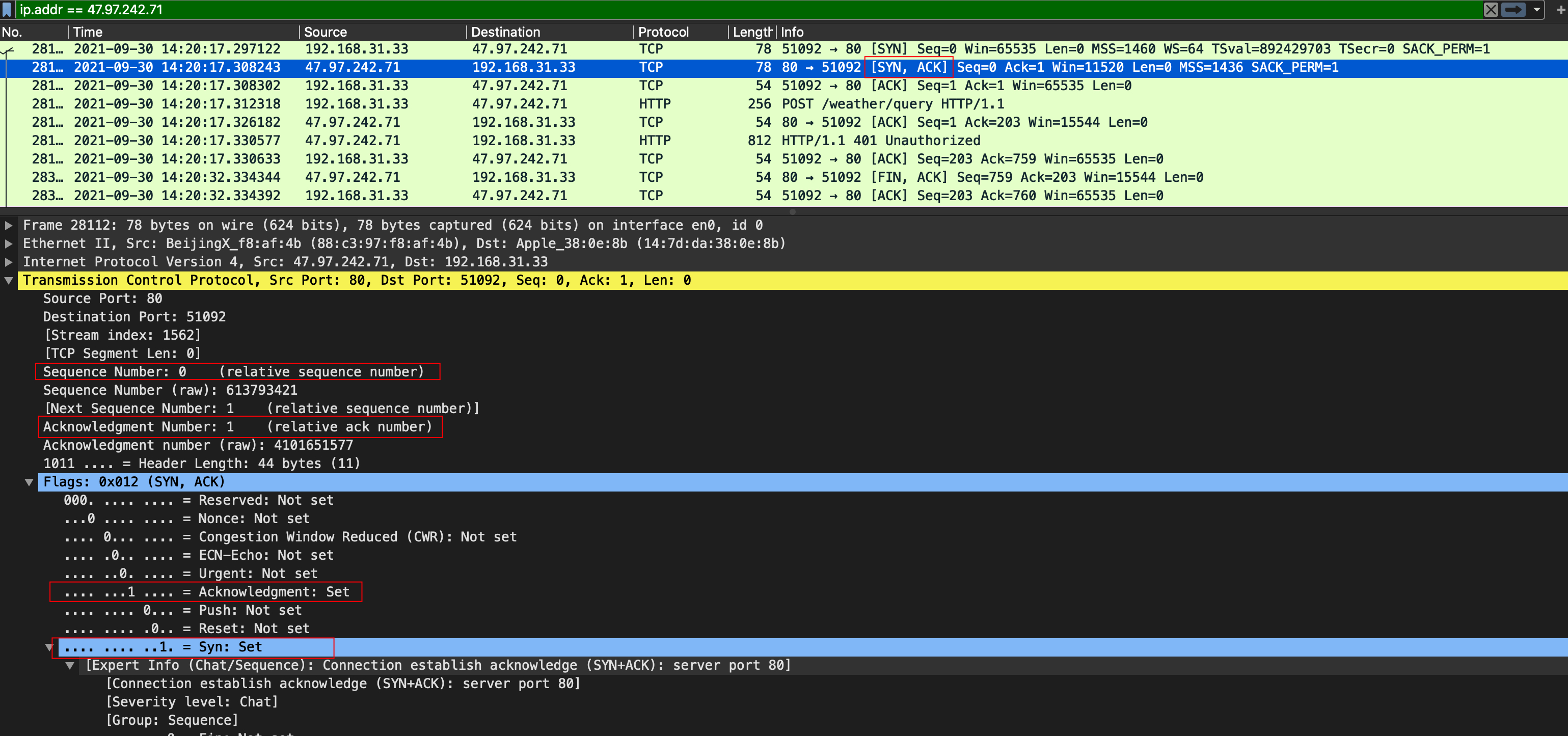
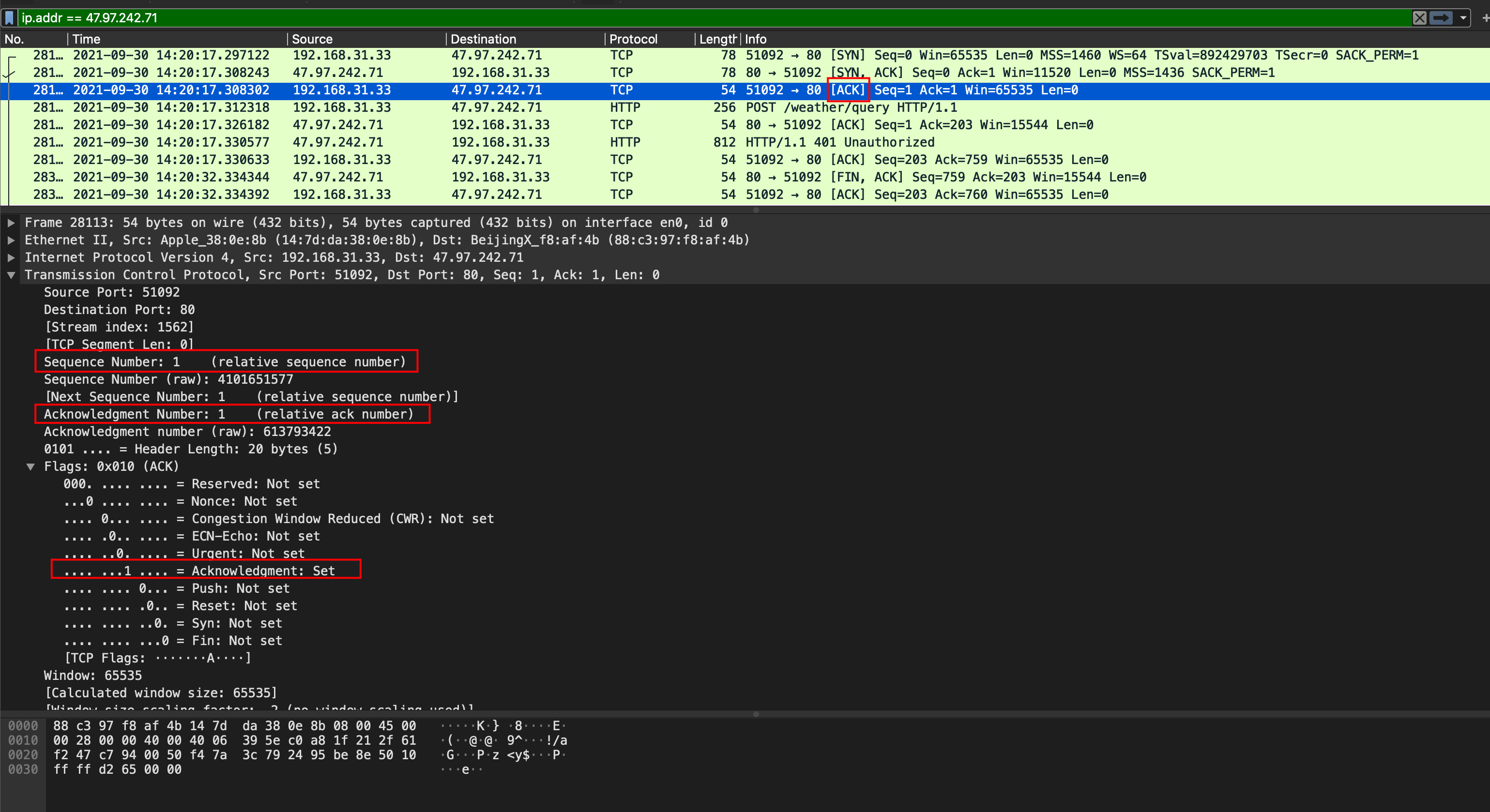
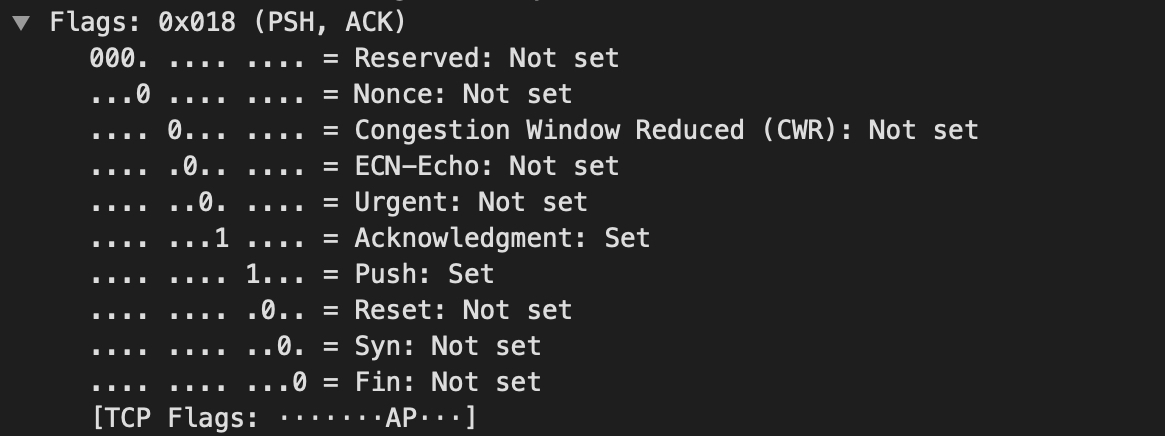
ICMP(Internet Control Message Protocol)Internet控制报文协议。它是TCP/IP协议簇的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。 ICMP协议是一种面向无连接的协议。
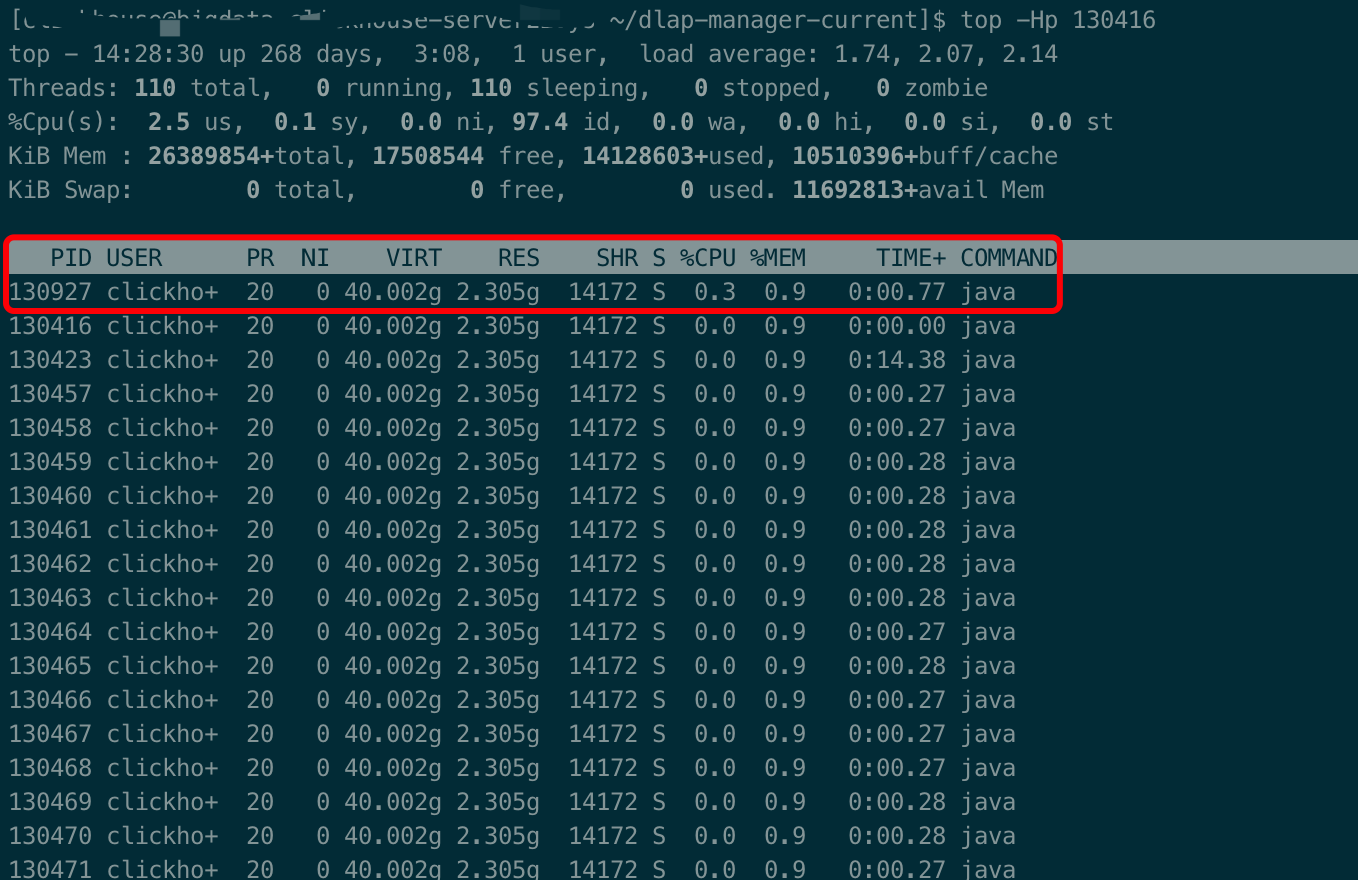
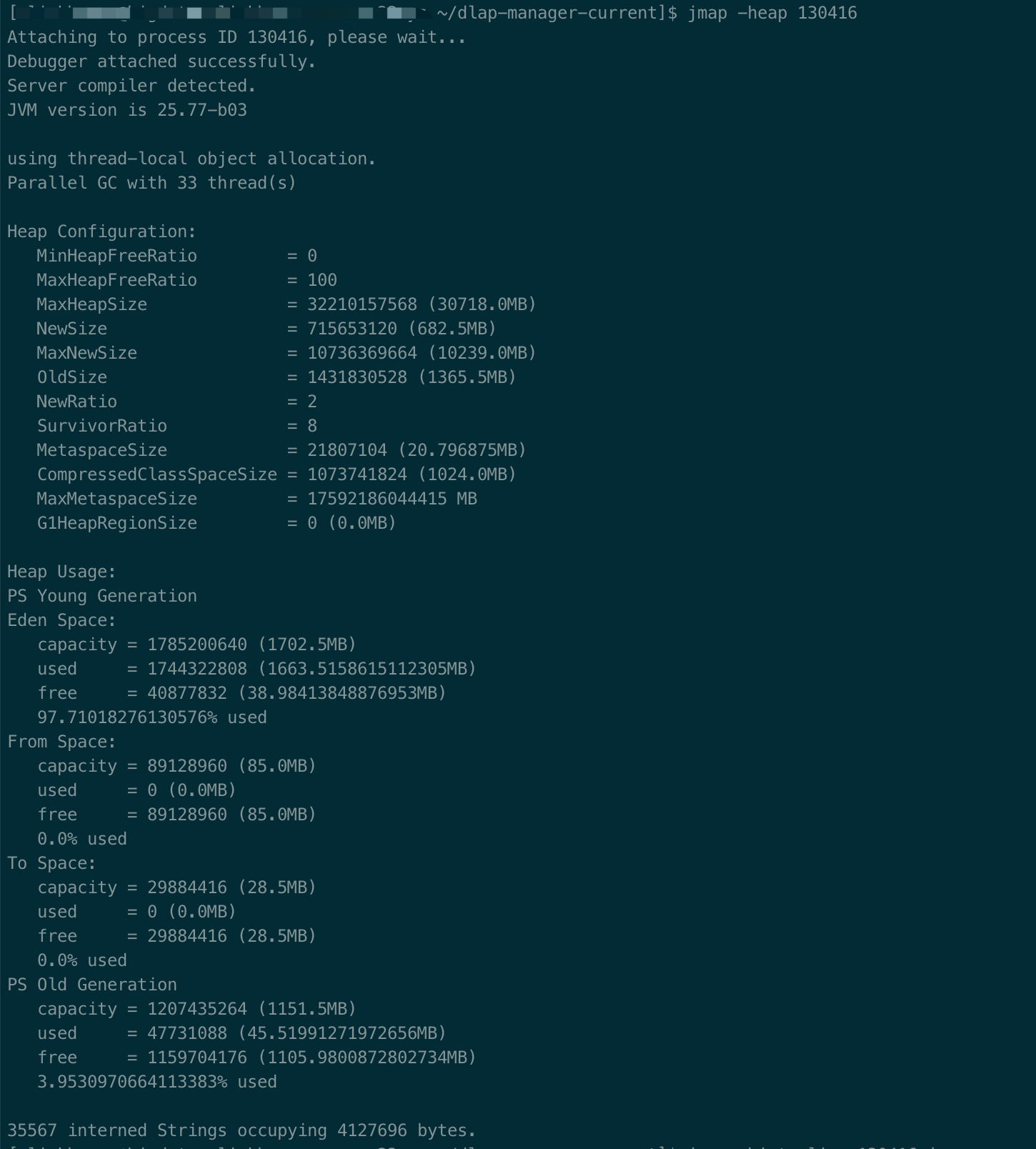
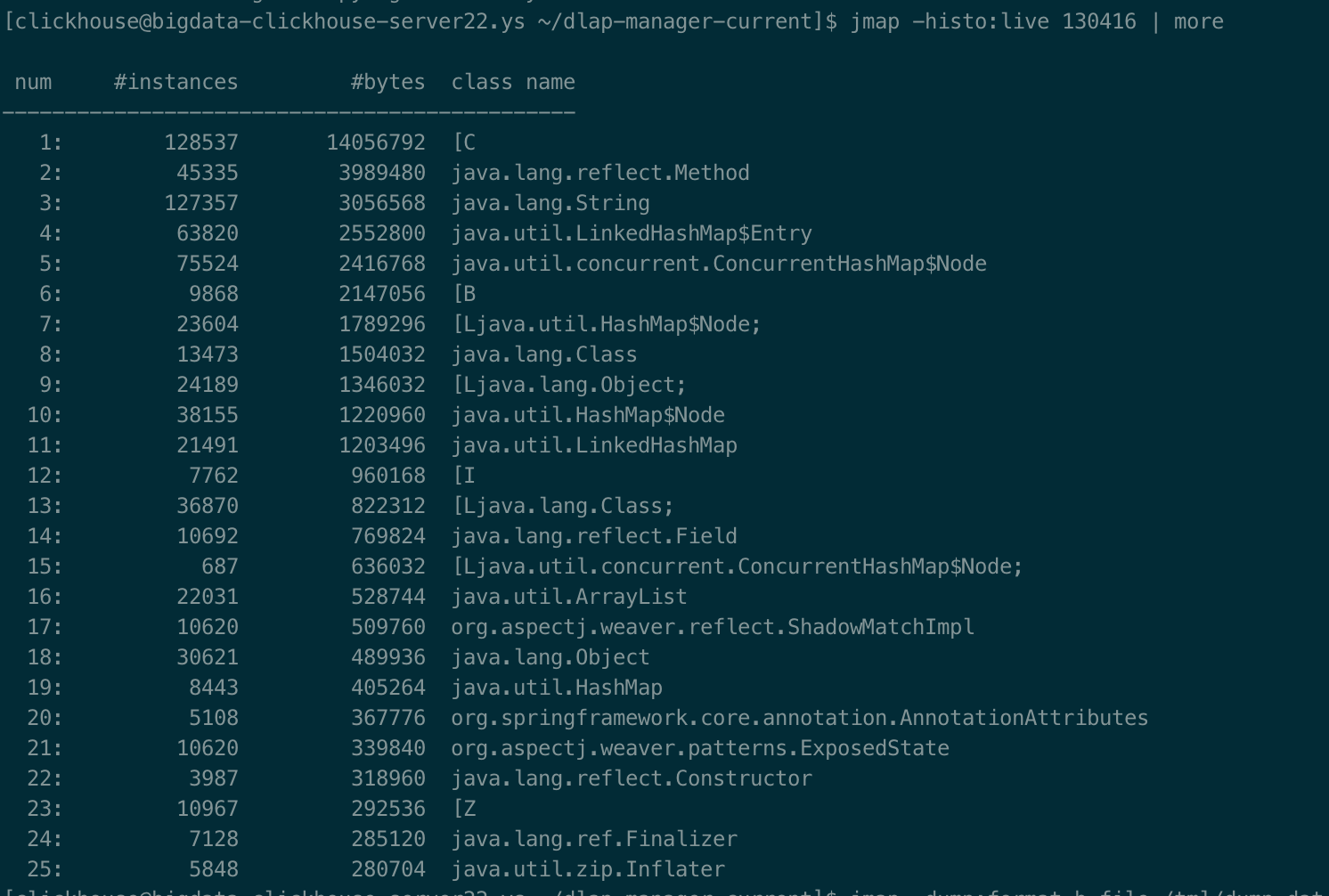
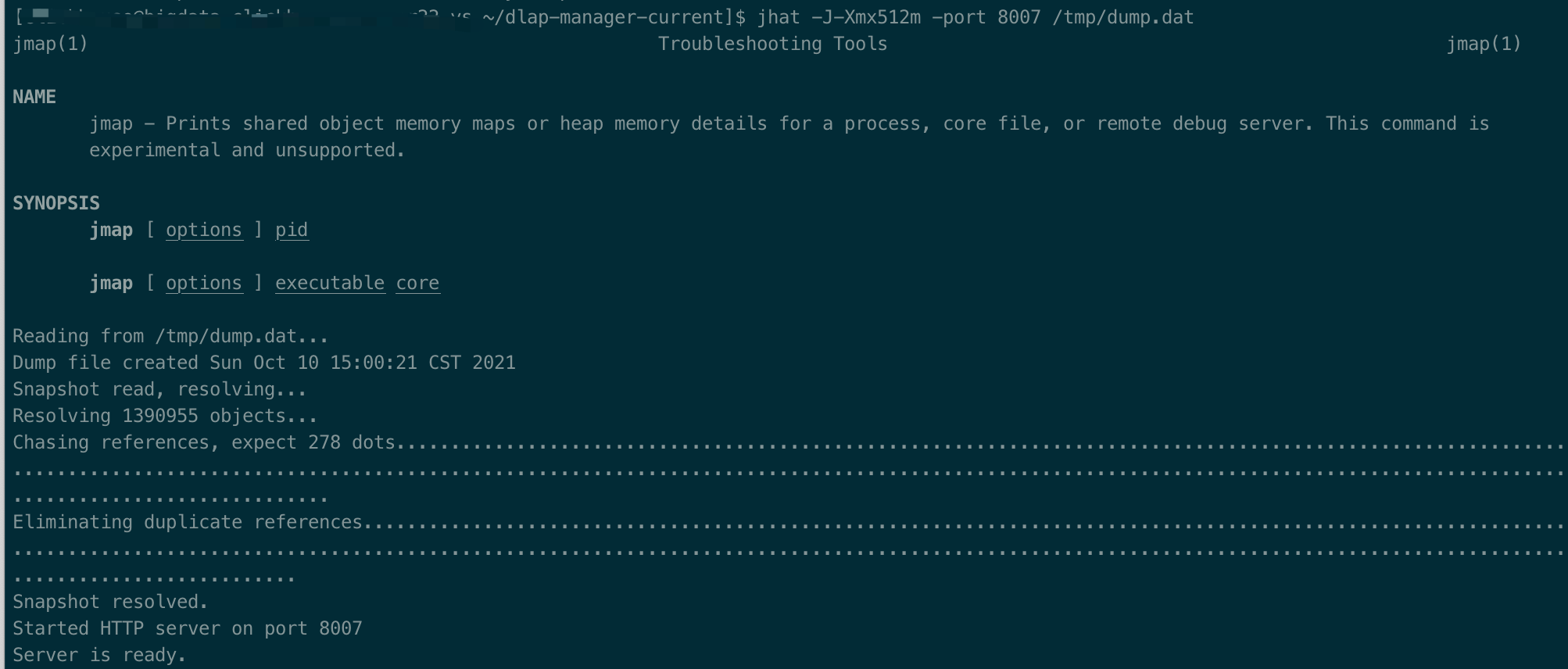
NAME jmap - Prints shared object memory maps or heap memory details for a process, core file, or remote debug server. This command is experimental and unsupported.
generalOption A single general command-line option -help or -options. See General Options.
outputOptions One or more output options that consist of a single statOption, plus any of the -t, -h, and -J options. See Output Options.
vmid Virtual machine identifier, which is a string that indicates the target JVM. The general syntax is the following:
[protocol:][//]lvmid[@hostname[:port]/servername]
The syntax of the vmid string corresponds to the syntax of a URI. The vmid string can vary from a simple integer that represents a local JVM to a more complex construction that specifies a communications protocol, port number, and other implementation-specific values. See Virtual Machine Identifier.
interval [s|ms] Sampling interval in the specified units, seconds (s) or milliseconds (ms). Default units are milliseconds. Must be a positive integer. When specified, the jstat command produces its output at each interval.
count Number of samples to display. The default value is infinity which causes the jstat command to display statistics until the target JVM terminates or the jstat command is terminated. This value must be a positive integer.
Option Name and Value Description Default --------------------- ----------- ------- heap=dump|sites|all heap profiling all cpu=samples|times|old CPU usage off monitor=y|n monitor contention n format=a|b text(txt) or binary output a file=<file> write data to file java.hprof[.txt] net=<host>:<port> send data over a socket off depth=<size> stack trace depth 4 interval=<ms> sample interval in ms 10 cutoff=<value> output cutoff point 0.0001 lineno=y|n line number in traces? y thread=y|n thread in traces? n doe=y|n dump on exit? y msa=y|n Solaris micro state accounting n force=y|n force output to <file> y verbose=y|n print messages about dumps y
OPTIONS -b, --bytes Display the amount of memory in bytes.
-k, --kilo Display the amount of memory in kilobytes. This is the default.
-m, --mega Display the amount of memory in megabytes.
-g, --giga Display the amount of memory in gigabytes.
--tera Display the amount of memory in terabytes.
-h, --human Show all output fields automatically scaled to shortest three digit unit and display the units of print out. Following units are used.
B = bytes K = kilos M = megas G = gigas T = teras
If unit is missing, and you have petabyte of RAM or swap, the number is in terabytes and columns might not be aligned with header.
-w, --wide Switch to the wide mode. The wide mode produces lines longer than 80 characters. In this mode buffers and cache are reported in two separate columns.
-c, --count count Display the result count times. Requires the -s option.
-l, --lohi Show detailed low and high memory statistics.
-s, --seconds seconds Continuously display the result delay seconds apart. You may actually specify any floating point number for delay, usleep(3) is used for microsecond resolu‐ tion delay times.
--si Use power of 1000 not 1024.
-t, --total Display a line showing the column totals.
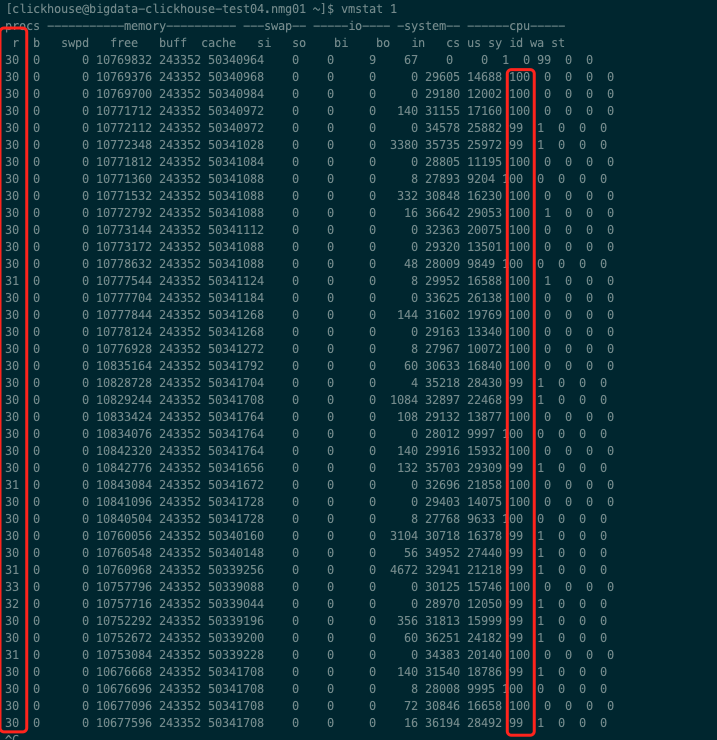
4、swap列 si 由内存进入内存交换区数量。 so 由内存交换区进入内存数量。 si、so的值长期为0,系统性能还是正常
5、IO列 bi 从块设备读入数据的总量(读磁盘)(每秒kb)。 bo 块设备写入数据的总量(写磁盘)(每秒kb) 这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
6、cpu列 cs 表示cpu的使用状态 us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。 sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足 id 列显示了cpu处在空闲状态的时间百分比 wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
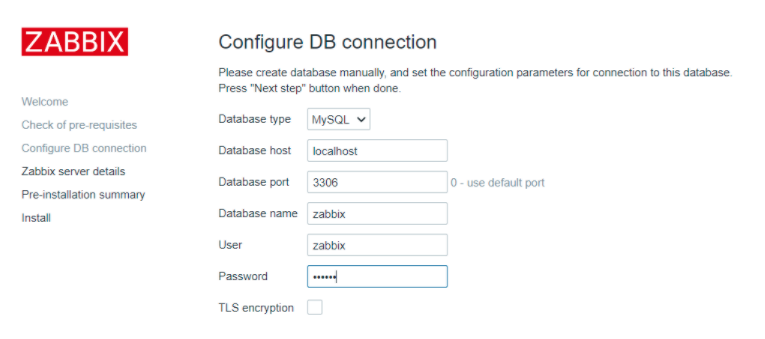
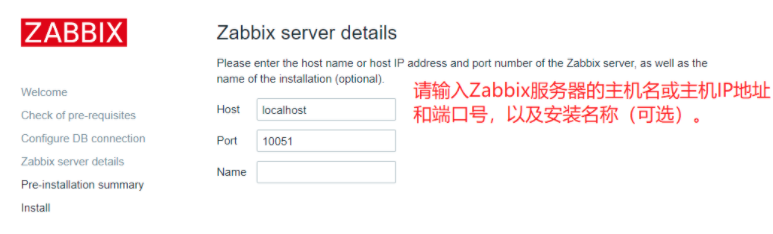
yum -y install epel-release wget tar wget https://cdn.zabbix.com/zabbix/sources/stable/5.0/zabbix-5.0.2.tar.gz tar zxvf zabbix-5.0.2.tar.gz cd zabbix-5.0.2