- grafana版本
生产环境:Grafana v6.6.2
本地docker安装相同版本:1
2
3
4
5
6
7
8
9
10sudo docker run -d --name grafana-662-1 \
-p 3000:3000 \
-e GF_DATABASE_TYPE=mysql \
-e GF_DATABASE_HOST=ip:port \
-e GF_DATABASE_NAME=grafana \
-e GF_DATABASE_USER=grafana \
-e GF_DATABASE_PASSWORD=mysql \
-e GF_DATABASE_URL=mysql://grafana:pwd@ip:port/grafana \
-v /data1/docker/grafana:/var/lib/grafana \
grafana/grafana:6.6.2
-e GF_xx,这个xx对应的是conf/grafana.ini(默认是default.ini)的[xx]
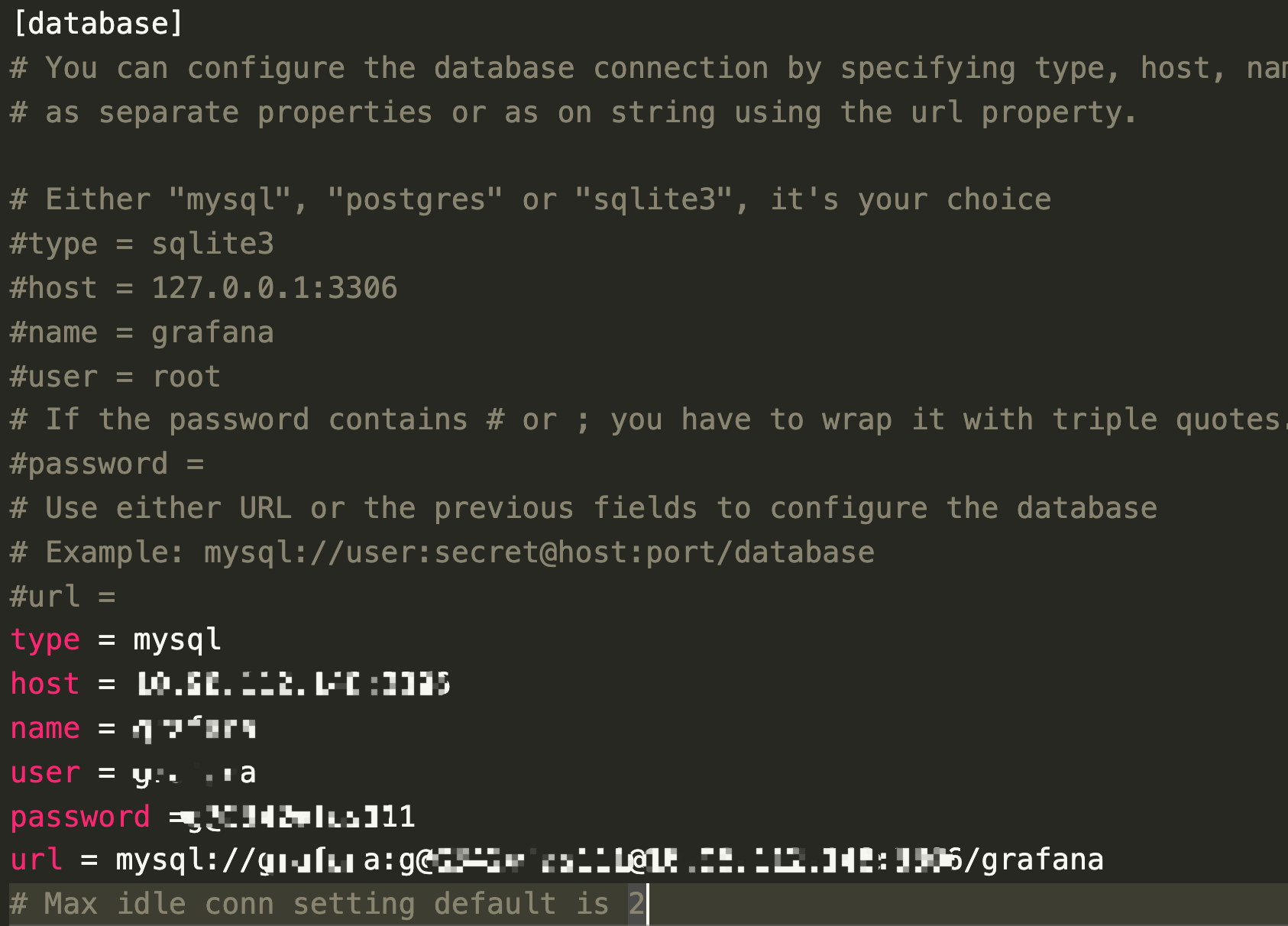
以上是用docker方式配置mysql启动grafana
确认mysql的35个表已经创建成功,暂停grafana
1
sudo docker stop $(sudo docker ps -a | grep grafana-662-1 | awk '{print $1}')
从本地mysql数据库导出表结构到生产环境
1
mysql -uroot -p -D grafana > grafana.sql
- 生产环境导入表结构
1
2CREATE DATABASE grafana CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
mysql -uroot -p -D grafana < grafana.sql - 另存脚本sqlitedump.sh
1
2
3
4
5
6
7
8
9#!/bin/bash
DB=$1
TABLES=$(sqlite3 $DB .tables | sed -r 's/(\S+)\s+(\S)/\1\n\2/g' | grep -v migration_log)
for t in $TABLES; do
echo "TRUNCATE TABLE $t;"
done
for t in $TABLES; do
echo -e ".mode insert $t\nselect * from $t;"
done | sqlite3 $DB 找到grafana.db文件
1
2cd /data1/docker/grafana
sh sqlitedump.sh grafana.db > insert.sql生产环境导入insert.sql
1
mysql -uroot -p -D grafana < 生产环境导入insert.sql
启动grafana的docker
1
sudo docker start $(sudo docker ps -a | grep grafana-662-1 | awk '{print $1}')
验证
打开web进行验证sqlite_master表
1
2
3
4
5
6
7
8sqlite3存在系统表sqlite_master,结构如下:
sqlite_master(
type TEXT, #类型:table-表,index-索引,view-视图
name TEXT, #名称:表名,索引名,视图名
tbl_name TEXT,
rootpage INTEGER,
sql TEXT
)slite3转mysql的python3脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123import sqlite3
import json
import re
class Sqlite3ToMysql():
def __init__(self):
dir = "grafana.db"
conn = sqlite3.connect(dir)
self.cur = conn.cursor()
def get_table_list(self):
self.cur.execute("select NAME from SQLITE_MASTER where TYPE='table' order by NAME;")
rows = self.cur.fetchall()
return rows
def get_table_column(self, tableName):
self.cur.execute("pragma table_info('{}');".format(tableName))
rows = self.cur.fetchall()
list = []
for (columnID, columnName, columnType,columnNotNull, columnDefault, columnPK) in rows:
dict = {
"name": columnName,
"type": columnType,
"null": "NOT NULL" if columnNotNull else "",
"default": "default '{}'".format(columnDefault) if columnDefault else "",
"pk": columnPK,
}
list.append(dict)
return list
def get_table(self, tableName):
self.cur.execute("SELECT * FROM `{}`;".format(tableName))
rows = self.cur.fetchall()
return rows
def get_table_index(self, tableName):
sql = "select sql from sqlite_master where tbl_name='{}' and type='index';".format(tableName)
self.cur.execute(sql)
rows = self.cur.fetchall()
if len(rows) == 0:
return {}
list = []
need = []
for row in rows:
value = str(row[0])
value = str.replace(value, "CREATE INDEX", "KEY")
value = str.replace(value, "CREATE UNIQUE INDEX", "UNIQUE KEY")
value = str.replace(value, "ON `{}`".format(tableName), "")
matchObj = re.findall(r"KEY\s*`.*`\s*\((.*)\)", value)
if len(matchObj) > 0:
tmp = matchObj[0].split(",")
for i in tmp:
i = str.replace(i, "`", "")
need.append(i)
list.append(" "+value)
return {"sql": ",\n".join(list) + ",\n", "need": need}
def ddl(self):
handle = open("ddl.sql","w")
rows = self.get_table_list()
for (tableName,) in rows:
handle.write("DROP TABLE IF EXISTS `{}`;\n".format(tableName))
handle.write("CREATE TABLE `{}`(\n".format(tableName))
tmp = self.get_table_column(tableName)
pk = ""
indexTmp = self.get_table_index(tableName)
for item in tmp:
# 对索引字段为text需要指定长度
typeStr = item["type"]
if len(indexTmp.keys()) > 0 and len(indexTmp["need"]) > 0 and typeStr == 'TEXT' and indexTmp["need"].count(item["name"]) > 0:
typeStr = "varchar(250)"
handle.write(" `{name}` {type} {null} {default},\n".format(
name=item["name"],
type=typeStr,
null=item["null"],
default=item["default"],
))
if item["pk"]:
pk = item["name"]
if len(indexTmp.keys()) == 0:
continue
else:
handle.write(indexTmp["sql"])
if (len(pk) > 0):
handle.write(" PRIMARY KEY (`{}`)\n".format(pk))
handle.write(") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;\n\n")
handle.close()
def dml(self):
handle = open("dml.sql","w")
rows = self.get_table_list()
for (tableName,) in rows:
list = self.get_table(tableName)
if len(list) == 0:
continue
handle.write("INSERT INTO `{}` VALUES \n".format(tableName))
itemList = []
for item in list:
valueList = []
for value in item:
if type(value) == bytes:
value = value.decode("utf-8")
if type(value) in [int, float, bool]:
value = "'" + str(value) + "'"
elif type(value) in [str]:
value = "'" + value + "'"
elif type(value) in [dict, list, tuple, set]:
value = "'" + json.dumps(value) + "'"
elif value is None:
value = "''"
valueList.append(value)
strTmp = "(" + "," . join(valueList) + ")"
itemList.append(strTmp)
handle.write(",".join(itemList))
handle.write("\n\n")
handle.close()
if __name__ == "__main__":
obj = Sqlite3ToMysql()
obj.ddl()
obj.dml()


{kind=link}