ClickHouse exception, code: 517, host: xx.xx.xx.xx, port: xxxx; Code: 517, e.displayText() = DB::Exception: Metadata on replica is not up to date with common metadata in Zookeeper. Cannot alter: Bad version
我们在修改表结构(例如alter table drop column xxx)时经常会遇到以上报错,原因副本上的元数据和在zookeeper上的元数据不一致,无法更新,因为版本号不一样。
class Base { public: virtual void print() { cout << "==BASE=="; } } class Derived: public Base { public: void print(){ cout << "==DERIVED==" } } int main() { Base *pointer = new Derived(); // ==DERIVED== pointer->print(); }
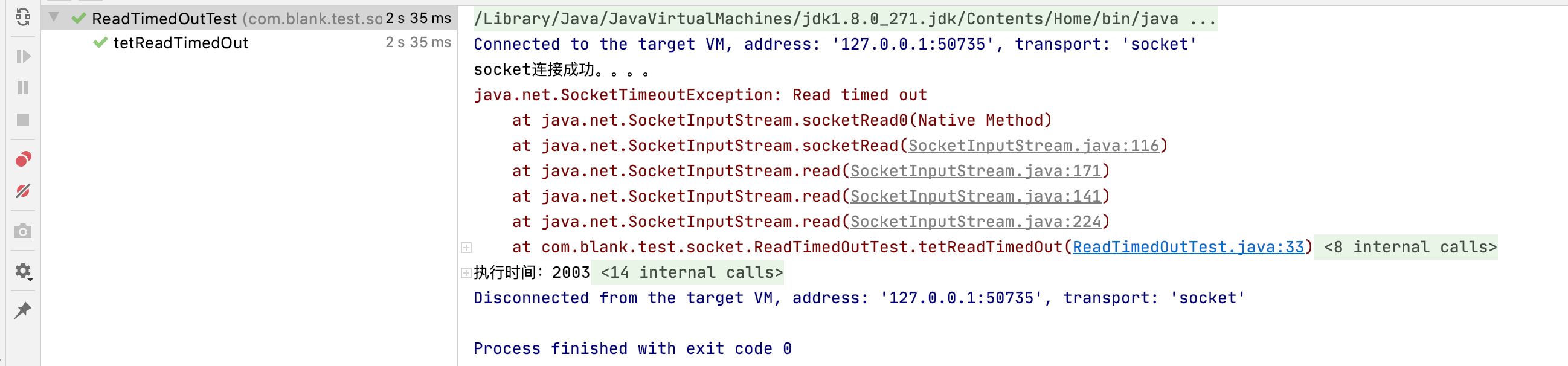
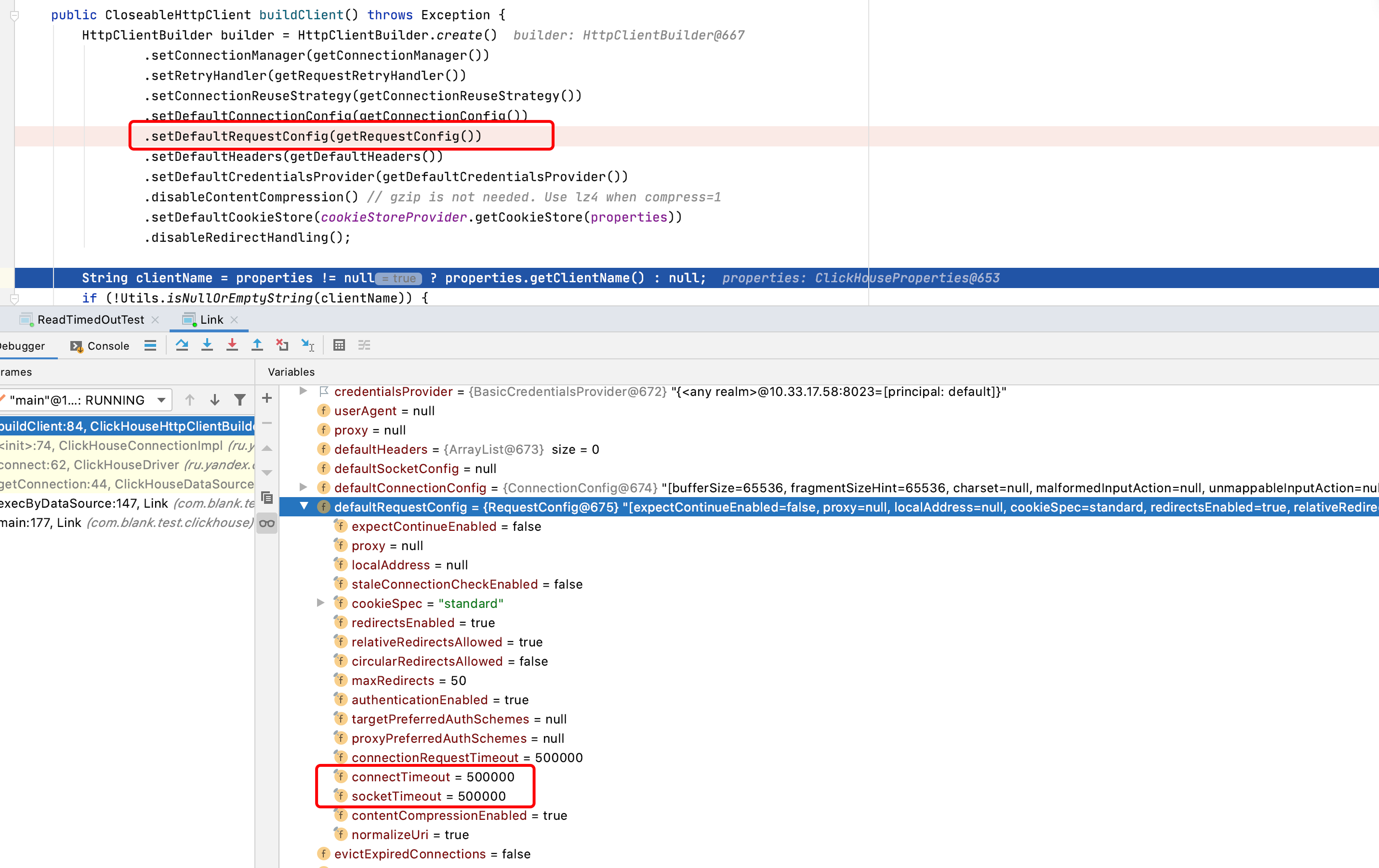
ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 159, host: bigdata-clickhouse-xxxx.ys, port: 8023; Read timed out at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.getException(ClickHouseExceptionSpecifier.java:86) at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.specify(ClickHouseExceptionSpecifier.java:56) at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.specify(ClickHouseExceptionSpecifier.java:25) at ru.yandex.clickhouse.ClickHouseStatementImpl.getInputStream(ClickHouseStatementImpl.java:797) at ru.yandex.clickhouse.ClickHouseStatementImpl.getLastInputStream(ClickHouseStatementImpl.java:691) at ru.yandex.clickhouse.ClickHouseStatementImpl.executeQuery(ClickHouseStatementImpl.java:340) at ru.yandex.clickhouse.ClickHouseStatementImpl.executeQuery(ClickHouseStatementImpl.java:324) at ru.yandex.clickhouse.ClickHouseStatementImpl.executeQuery(ClickHouseStatementImpl.java:319) at ru.yandex.clickhouse.ClickHouseStatementImpl.executeQuery(ClickHouseStatementImpl.java:314) at
/** * Here we expect the ClickHouse error message to be of the following format: * "Code: 10, e.displayText() = DB::Exception: ...". */ private static ClickHouseException specify(String clickHouseMessage, Throwable cause, String host, int port) { if (Utils.isNullOrEmptyString(clickHouseMessage) && cause != null) { return getException(cause, host, port); }
try { int code; if (clickHouseMessage.startsWith("Poco::Exception. Code: 1000, ")) { code = 1000; } else { // Code: 175, e.displayText() = DB::Exception: code = getErrorCode(clickHouseMessage); } // ошибку в изначальном виде все-таки укажем Throwable messageHolder = cause != null ? cause : new Throwable(clickHouseMessage); if (code == -1) { return getException(messageHolder, host, port); }
return new ClickHouseException(code, messageHolder, host, port); } catch (Exception e) { log.error("Unsupported ClickHouse error format, please fix ClickHouseExceptionSpecifier, message: {}, error: {}", clickHouseMessage, e.getMessage()); return new ClickHouseUnknownException(clickHouseMessage, cause, host, port); } } private static ClickHouseException getException(Throwable cause, String host, int port) { if (cause instanceof SocketTimeoutException) // if we've got SocketTimeoutException, we'll say that the query is not good. This is not the same as SOCKET_TIMEOUT of clickhouse // but it actually could be a failing ClickHouse { return new ClickHouseException(ClickHouseErrorCode.TIMEOUT_EXCEEDED.code, cause, host, port); } else if (cause instanceof ConnectTimeoutException || cause instanceof ConnectException) // couldn't connect to ClickHouse during connectTimeout { return new ClickHouseException(ClickHouseErrorCode.NETWORK_ERROR.code, cause, host, port); } else { return new ClickHouseUnknownException(cause, host, port); } }
/** * Signals that a timeout has occurred on a socket read or accept. * * @since 1.4 */
public class SocketTimeoutException extends java.io.InterruptedIOException { private static final long serialVersionUID = -8846654841826352300L;
/** * Constructs a new SocketTimeoutException with a detail * message. * @param msg the detail message */ public SocketTimeoutException(String msg) { super(msg); }
/** * Construct a new SocketTimeoutException with no detailed message. */ public SocketTimeoutException() {} }
在查询语句后面增加 LOCK IN SHARE MODE ,Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。 其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。 加上共享锁后,对于update,insert,delete语句会自动加排它锁。
举例说明
1 2 3 4 5 6
# 在A窗口输入 select * from lock where id = 1 lock in shard mode # 在B窗口输入 update lock set version = version + 1 where id = 1 # B窗口报错 [Err] 1205 - Lock wait timeout exceeded; try restarting transaction
# 要使用排他锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交 # 在A窗口输入 set autocommit = 0; begin; select * from lock where id = 1 for update; update lock set version = version + 1 where id = 1; commit;
# 在B窗口输入,会看到一直在等待中,直到A窗口释放锁,B窗口才能获取结果 select * from lock where id = 1 for update;
# 是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁 # InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求 # 指同一个事务内多次查询返回的结果集不一样。比如同一个事务 A 第一次查询时候有 n 条记录,但是第二次同等条件下查询却有 n+1 条记录,这就好像产生了幻觉。发生幻读的原因也是另外一个事务新增或者删除或者修改了第一个事务结果集里面的数据,同一个记录的数据内容被修改了,所有数据行的记录就变多或者变少了 Select * from emp where empid > 100 for update;
CREATE TABLE `job_lock` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL DEFAULT '0' COMMENT 'job名称', `timeout` bigint(20) NOT NULL DEFAULT '0' COMMENT '任务执行超时间隔,毫秒', `status` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'job状态:0-空闲,1-运行', `description` varchar(255) NOT NULL DEFAULT '' COMMENT 'job描述', `gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `gmt_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', `version` bigint(20) NOT NULL DEFAULT '0' COMMENT '版本', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
加锁方法
1 2 3 4 5 6 7
<update id="requireLock" parameterType="java.util.Map"> <![CDATA[ update job_lock set status = 1, version=version + 1 where id = #{id} and version =#{version} and status = 0 ]]> </update>
解锁方法
1 2 3 4 5 6 7
<update id="releaseLock" parameterType="java.util.Map"> <![CDATA[ update job_lock set status = 0 where id = #{id} and status = 1 ]]> </update>
注意,您不能同时通过两种配置方法来管理同一访问实体。(You can’t manage the same access entity by both configuration methods simultaneously.) users.xml有三大块进行说明,分别为:profiles,quotas,users,主要配置如下所示:
Code: 201. DB::Exception: Received from localhost:9000. DB::Exception: Quota for user `default` for 10s has been exceeded: queries = 4/3. Interval will end at 2020-04-02 11:29:40. Name of quota template: `default`.
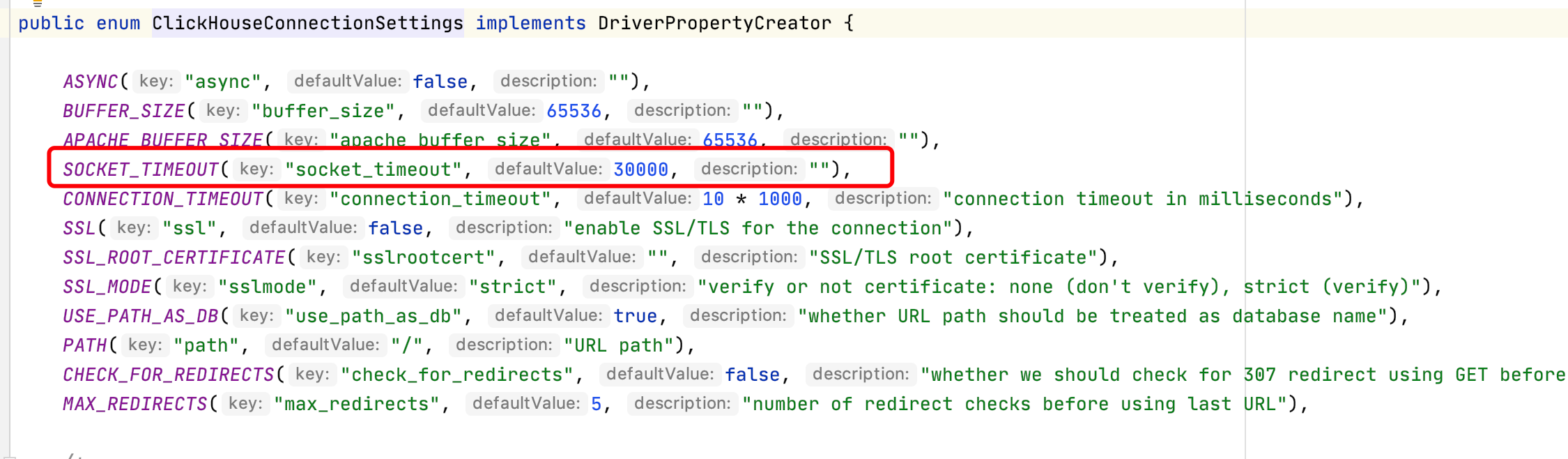
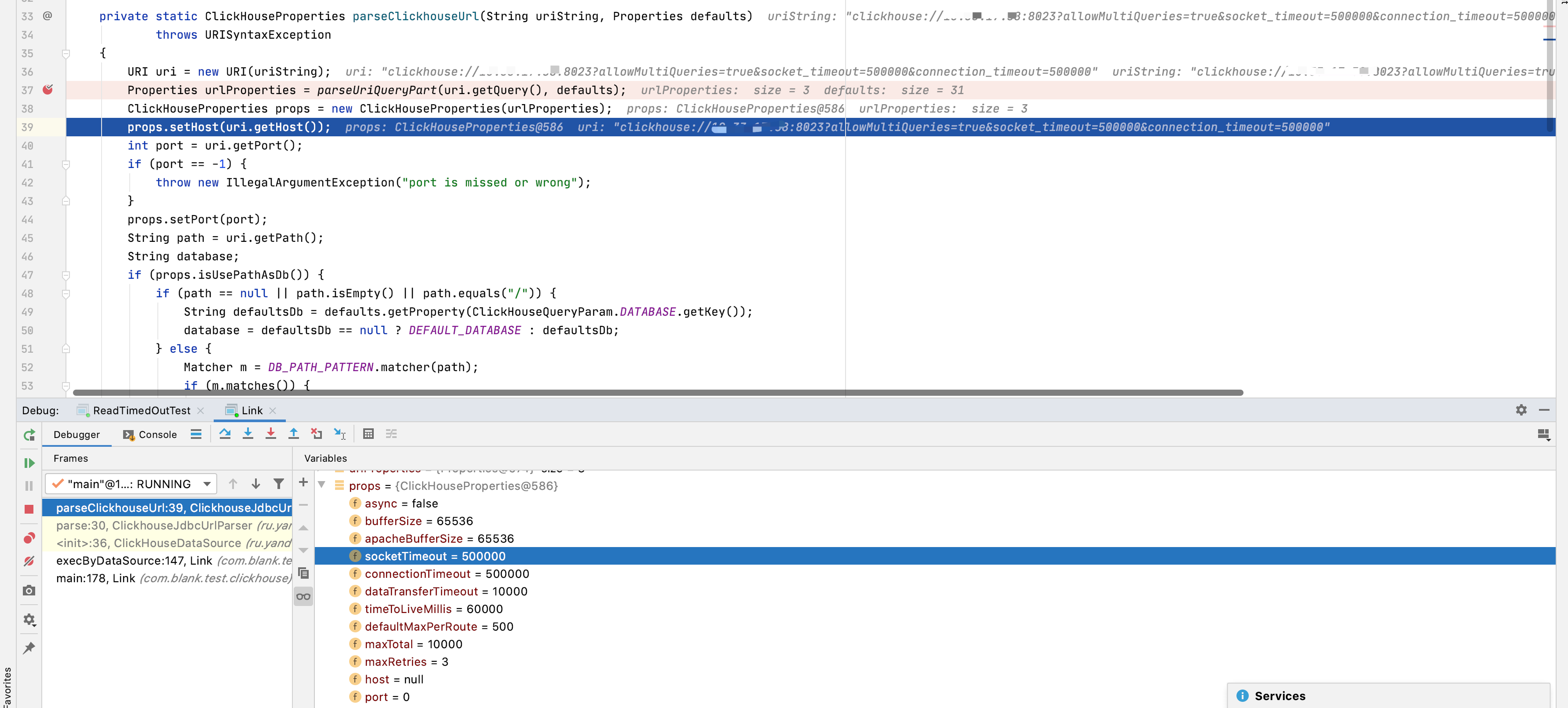
Code: 452, e.displayText() = DB::Exception: Setting max_memory_usage should not be greater than 20000000000. Code: 452, e.displayText() = DB::Exception: Setting max_memory_usage should not be less than 5000000000.
查询超过了最大使用内存
user限制
1
Code: 516, e.displayText() = DB::Exception: prod_dlap_manager: Authentication failed: password is incorrect or there is no user with such name (version 206.1.1)
用户不存在,或者用户的密码错误
改进方案
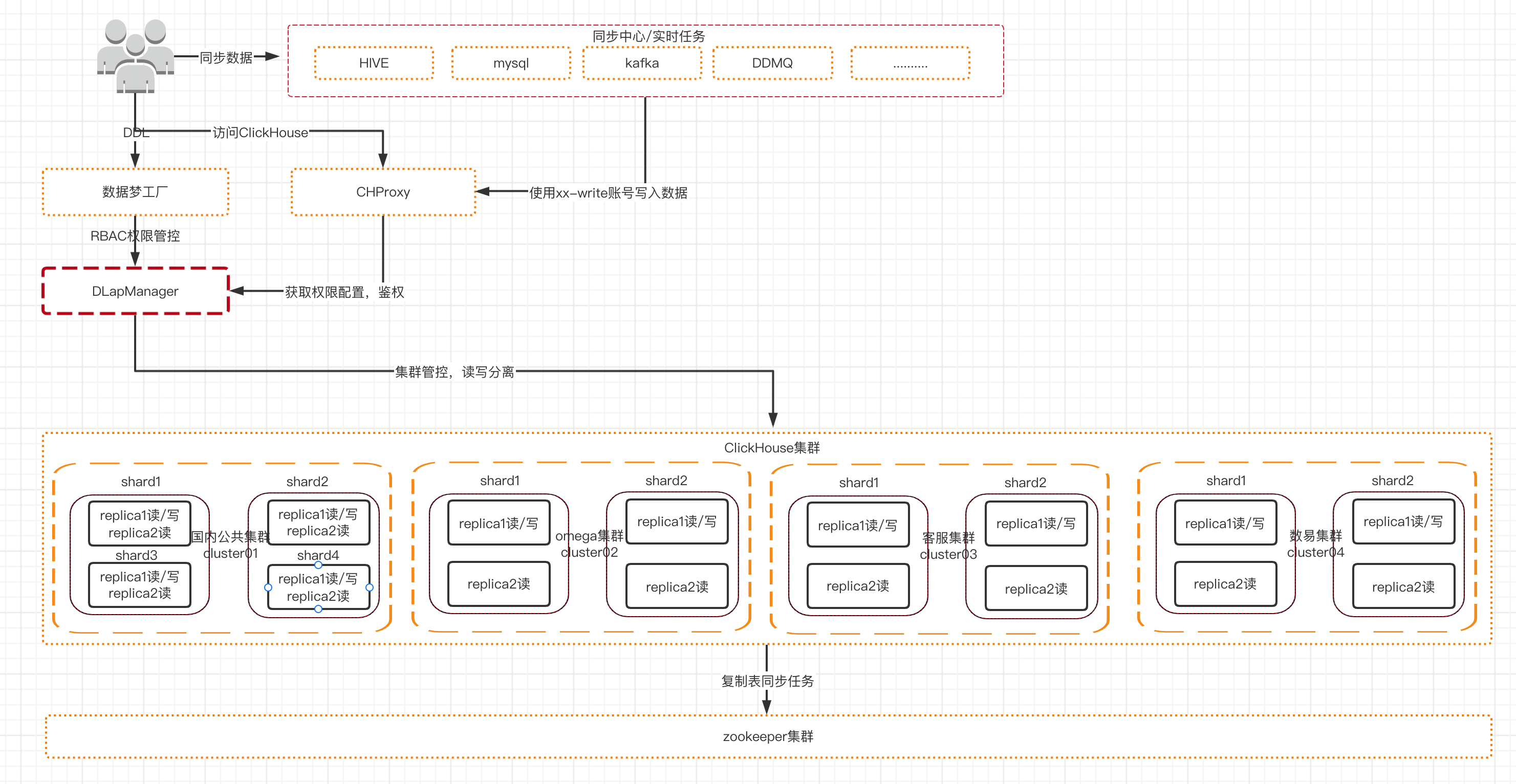
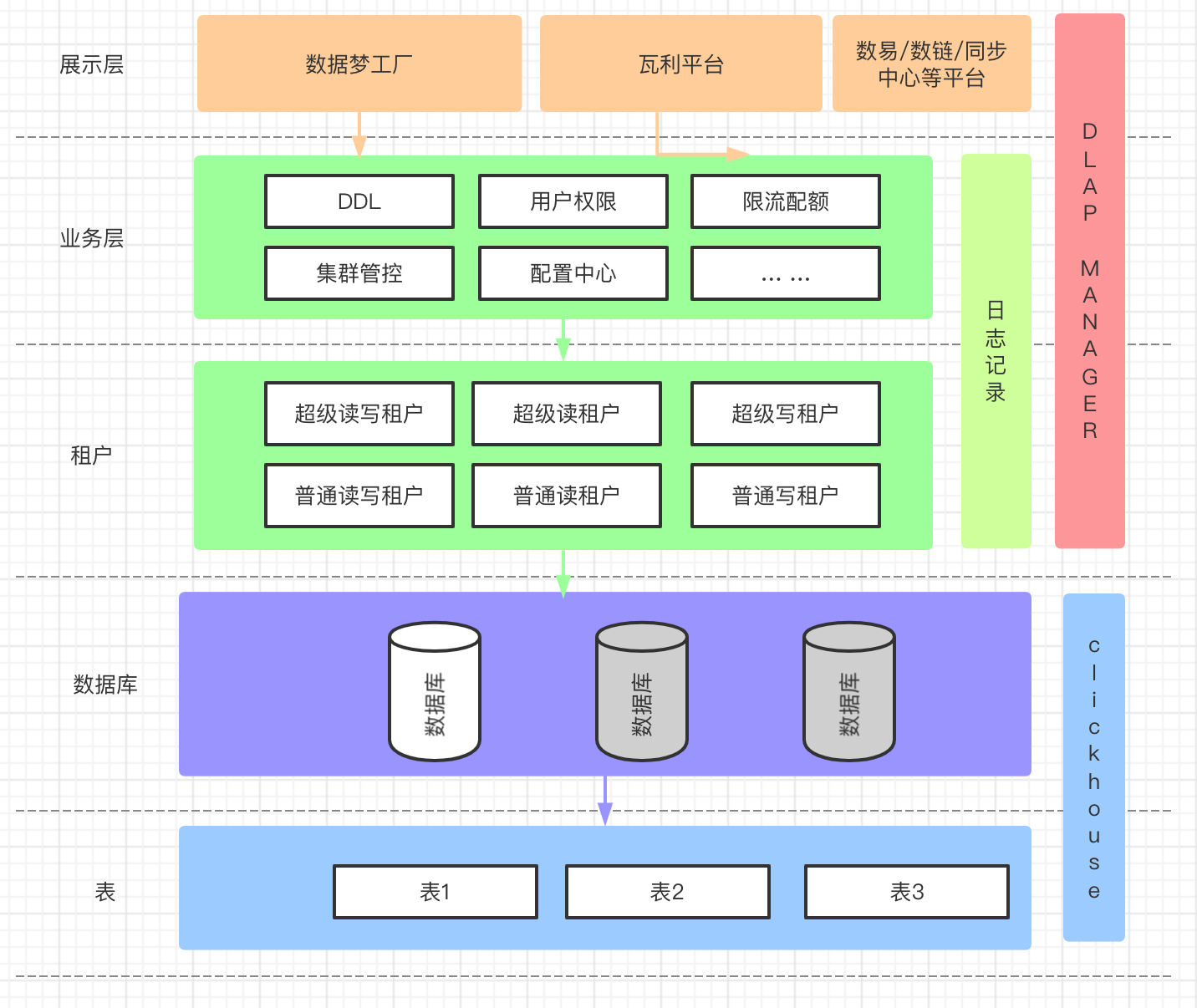
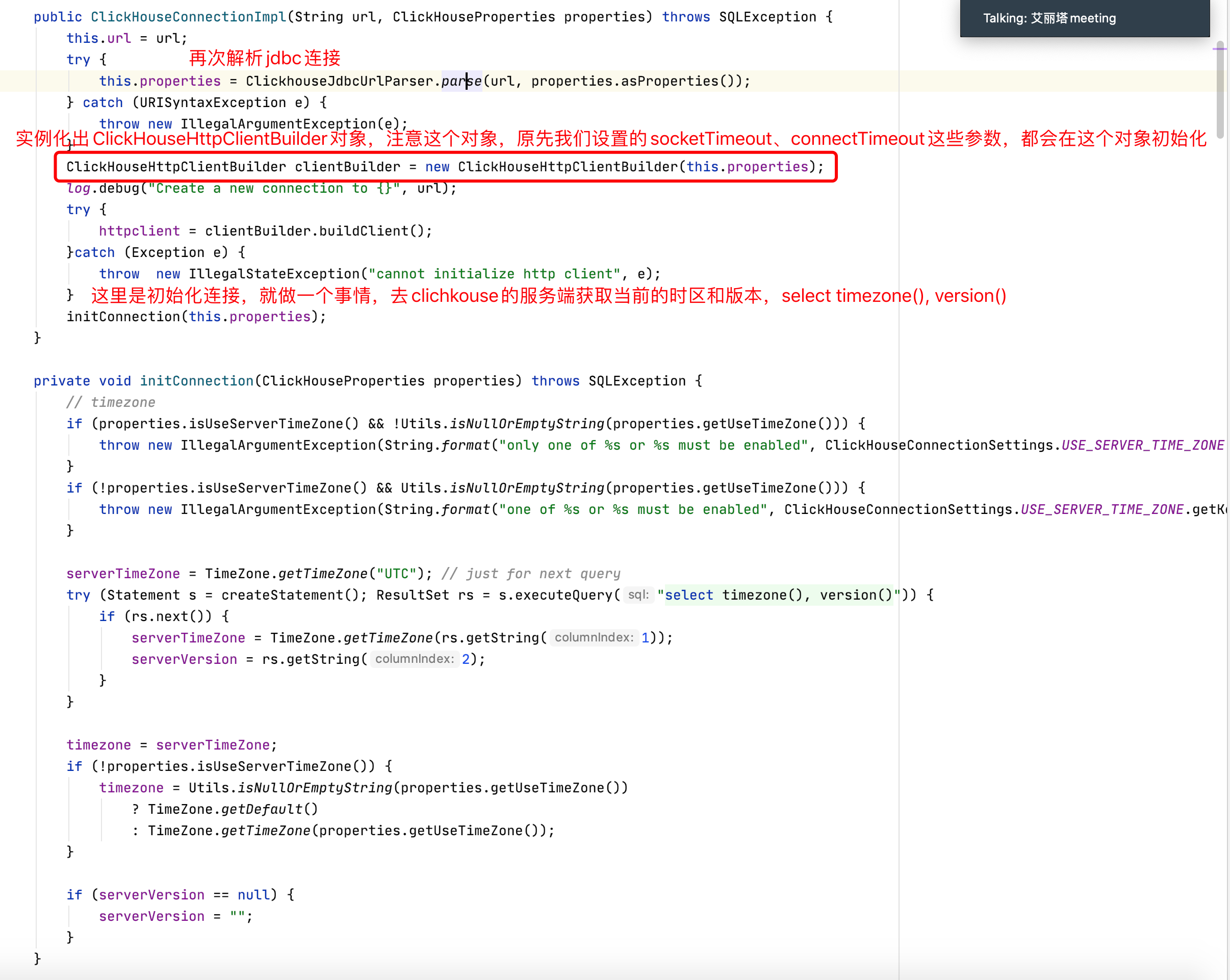
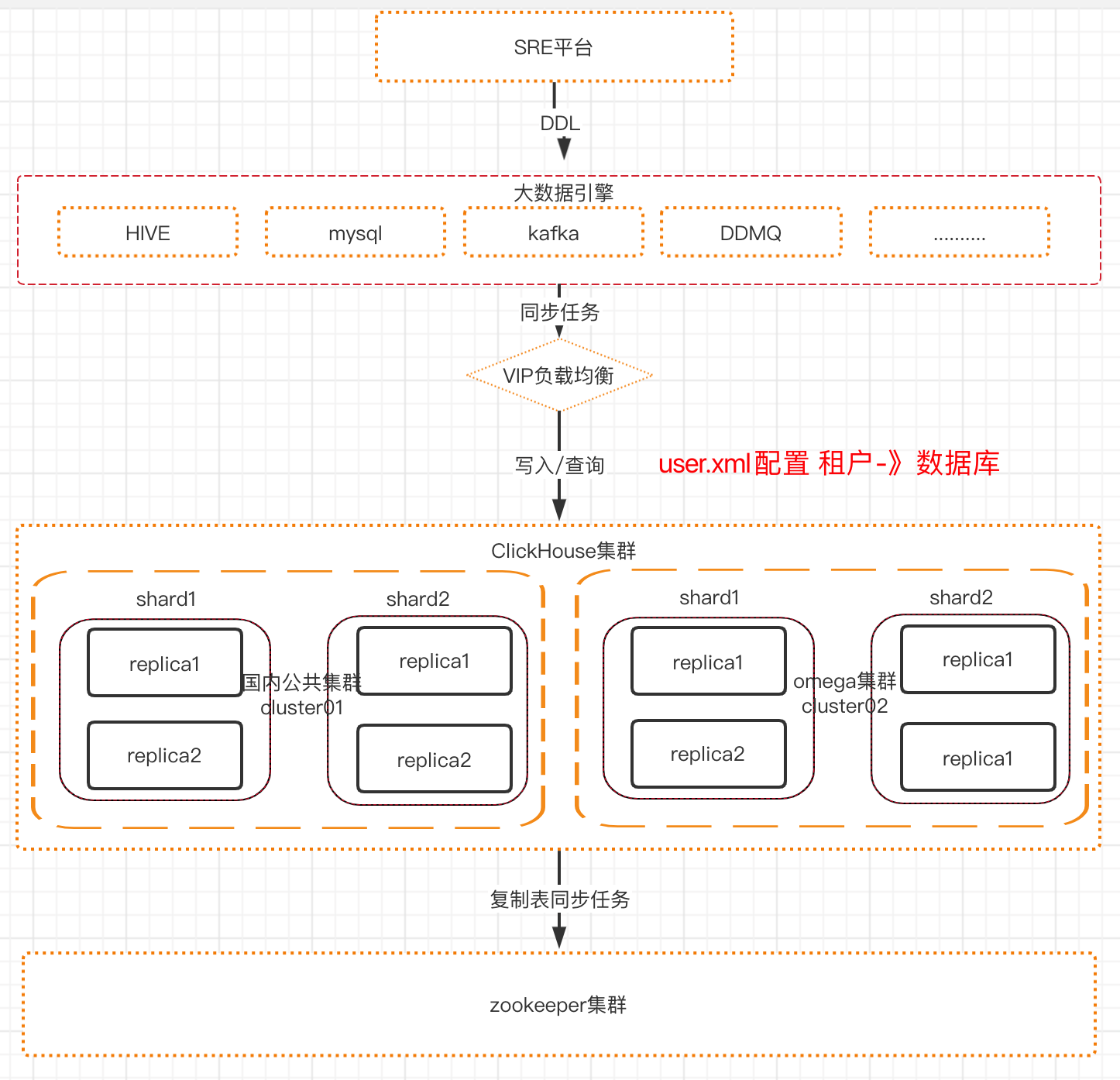
经过对clickhouse的权限相关了解之后,我们在2021年8月进行了一次权限升级方案改造,通过default用户创建出超级管理员super_admin及普通管理员admin(如果在user.xml里定义了super_admin用户,之后就无法修改,若修改则直接报错Cannot update user admin in users.xml because this storage is readonly),以超级管理员的身份给超级租户和普通租户赋权,可以通过SQL的方式进行权限的CRUD,以达到动态分配集群资源的目的。 经过拆分后,我们单独自研了DlapManager组件,用以管控Clickhouse集群读写节点、zookeeper组件、CHProxy组件(采用开源工具快速接入以实现读写ck角色的区分,达到数据写入均衡查询均衡的 目的,链接),而CHProxy组件需要的集群读写资源则通过DlapManager角色进行实时更新和生产,而外部平台业务方直接调用DlapManager组件对外开放的api进行库表的所有DDL操作,目前我们的所有普通租户均是用户通过数据梦工厂的创建项目开通实时权限后,我们会自动创建一个租户在Clickhouse这边,当该租户进行库表DDL后,DlapManager组件就会生成相应的DDL任务队列,队列以异步线程方式实时发往对应的集群,以下的DlapManager组件的系统架构设计图:
CREATE USER super_admin; GRANT ALL ON *.* TO super_admin WITH GRANT OPTION; CREATE USER admin;
创建profiles设置
1
CREATE SETTINGS PROFILE IF NOT EXISTS didi_profile SETTINGS readonly = 2 READONLY
创建quota配额
1 2 3
CREATE QUOTA IF NOT EXISTS didi_quota FOR INTERVAL 10 second MAX queries 1
创建角色
1
CREATE ROLE IF NOT EXISTS didi_role
赋予 Role 权限
1 2
# 允许didi_role这个角色可以访问库名叫db的所有表的查询权限 GRANT SELECT ON db.* TO didi_role
创建一个回收角色,用以回收不使用的profile、quota
1
REATE ROLE IF NOT EXISTS gc_role
Role 绑定 Profile, Quota
1 2
ALTER SETTINGS PROFILE didi_profile TO didi_role; ALTER QUOTA didi_quota TO didi_role;
应用到租户
1
GRANT didi_role TO super_admin
验证租户角色
1
SELECT * FROM system.role_grants WHERE user_name LIKE 'admin'
修改用户的quota(当用户的读/写超过了限额后需要给用户扩容)
1 2 3 4 5 6 7 8 9 10 11
# 先创建新quota CREATE QUOTA IF NOT EXISTS new_quota FOR INTERVAL 5 second MAX queries 1; # 将原先的didi_quota绑定到gc_role ALTER QUOTA didi_quota TO gc_role; # 绑定新quota ALTER QUOTA new_quota TO didi_role; # 刷新admin的角色 revoke didi_role from admin; grant didi_role to admin; # double check检查 SELECT name, apply_to_list FROM system.quotas WHERE name LIKE 'new_quota'
修改用户的profile(当用户的读/写超过了限额后需要给用户扩容)
1 2 3 4 5 6 7 8 9 10 11
# 先创建新profile CREATE SETTINGS PROFILE IF NOT EXISTS new_profile SETTINGS readonly = 0 READONLY; # 将原先的didi_profile绑定到gc_role ALTER SETTINGS PROFILE didi_profile TO gc_role # 绑定新profile ALTER SETTINGS PROFILE new_profile TO didi_role; # 刷新admin的角色 revoke didi_role from admin; grant didi_role to admin; # double check检查 SELECT name, apply_to_list FROM system.settings_profiles WHERE name LIKE 'new_quota'
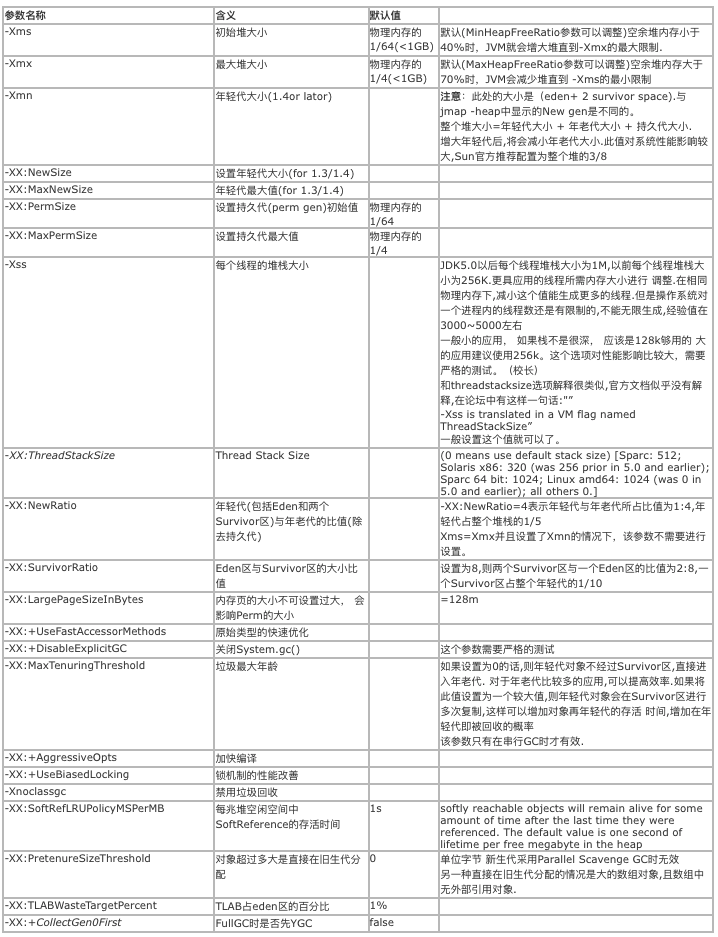
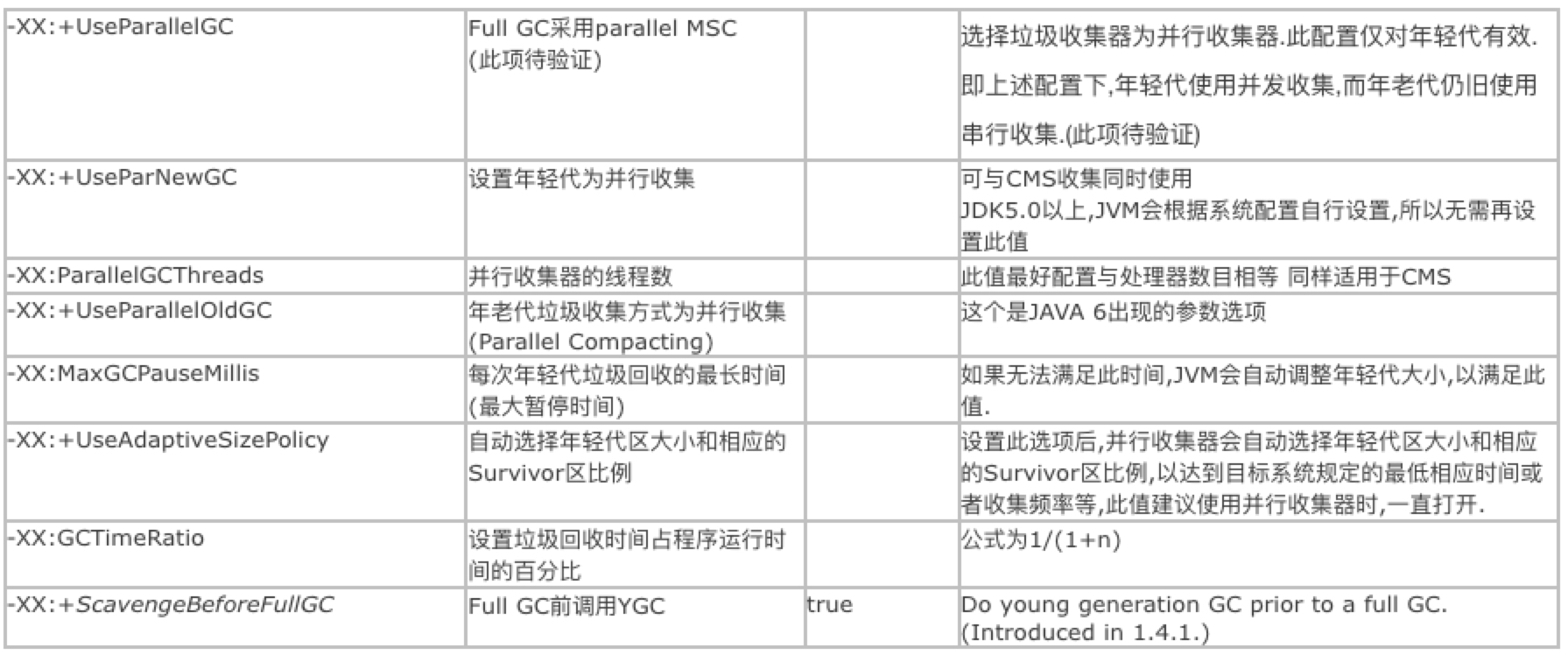
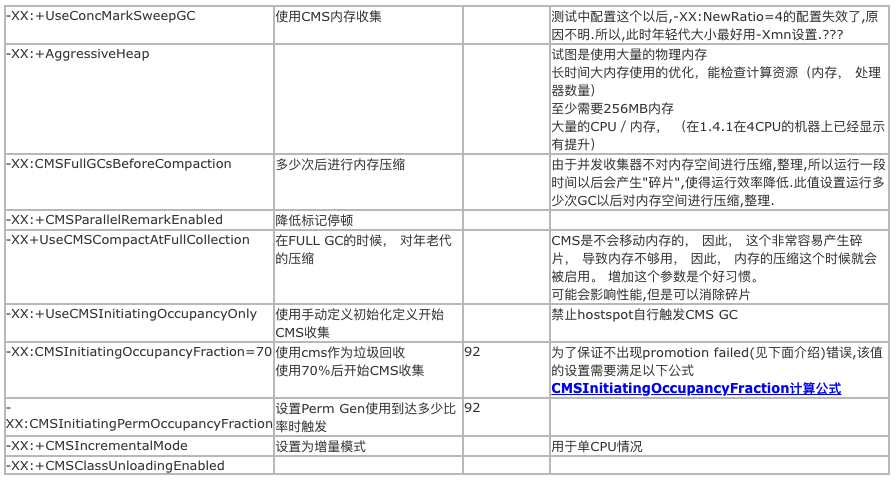
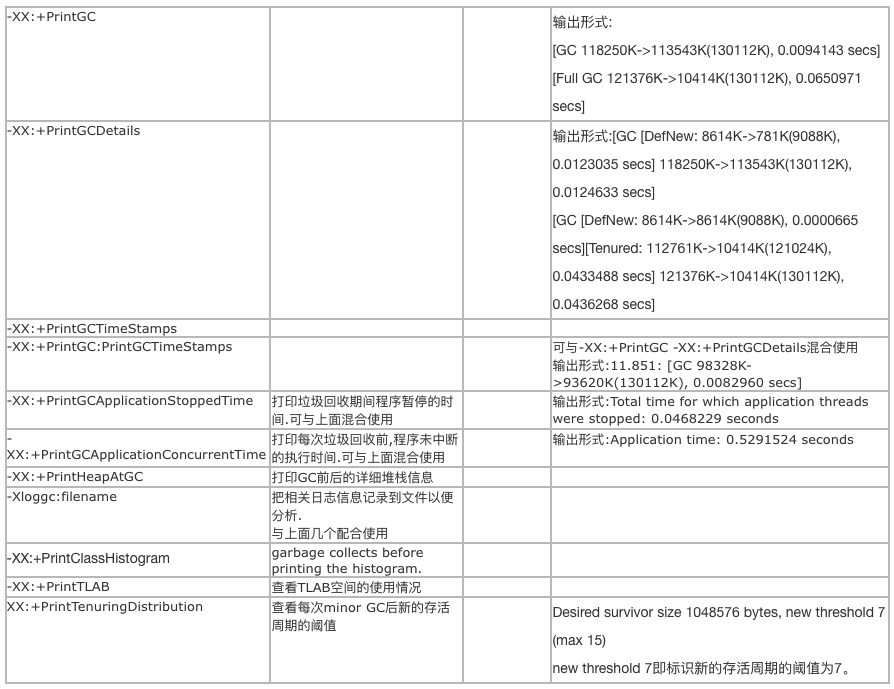
知道答案是-XX:InitialHeapSize=2147483648和-XX:MaxHeapSize=32210157568。另外通过 jvm默认配置发现这一段Server JVM Default Initial and Maximum Heap Sizes
The default initial and maximum heap sizes work similarly on the server JVM as it does on the client JVM, except that the default values can go higher. On 32-bit JVMs, the default maximum heap size can be up to 1 GB if there is 4 GB or more of physical memory. On 64-bit JVMs, the default maximum heap size can be up to 32 GB if there is 128 GB or more of physical memory. You can always set a higher or lower initial and maximum heap by specifying those values directly; see the next section.中文意思就是32位系统默认最大值可以到1GB,如果物理内存大于或者等于4GB,而在64位系统默认最大堆内存可以达到32GB或者更多,如果物理内存大袋128GB或者更多时。 但是要注意过多的
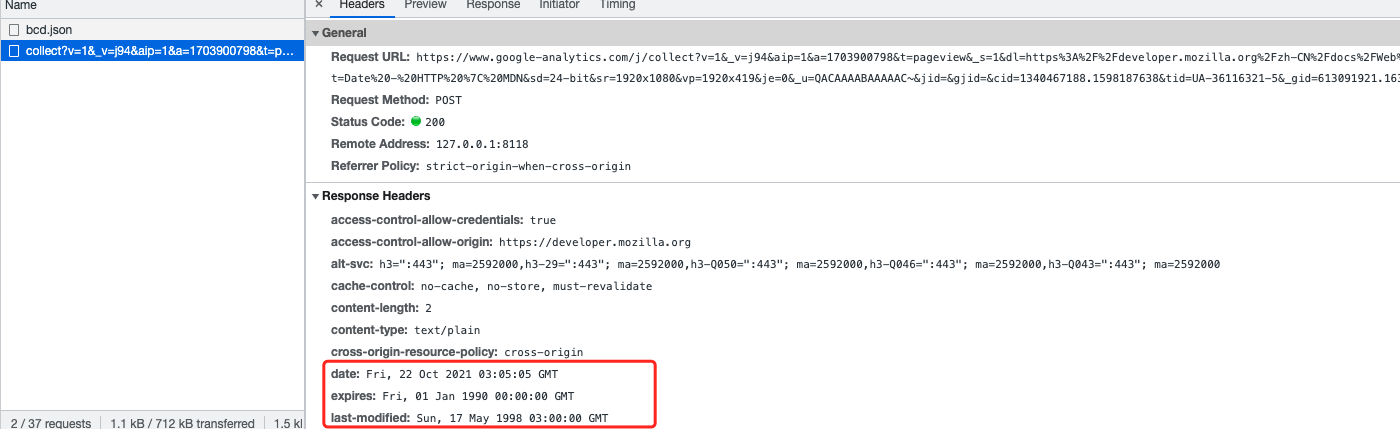
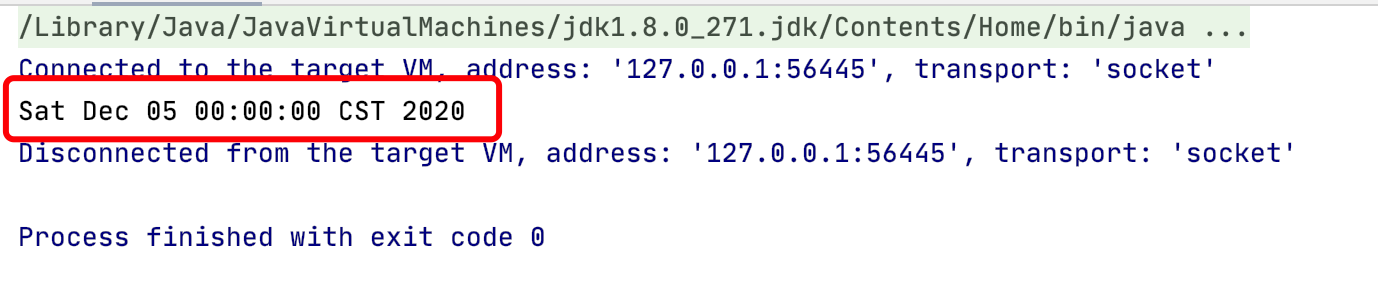
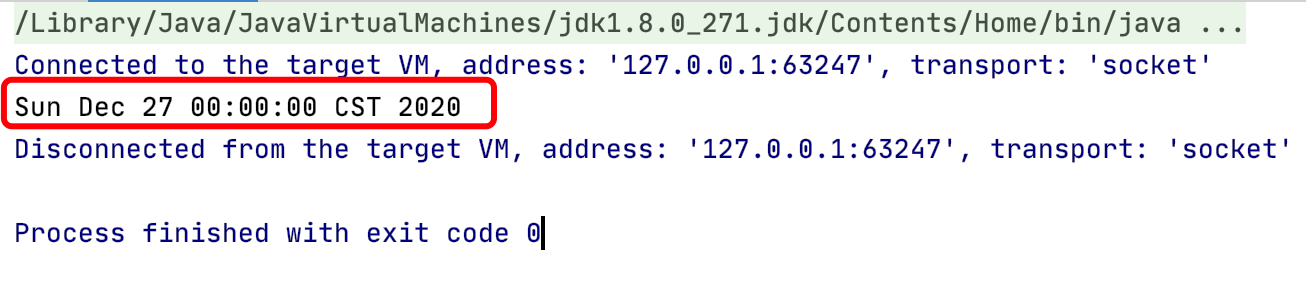
格林尼治平时(Greenwich Mean Time,GMT),又称为格林尼治标准时间。 格林尼治平时的正午是指当平太阳横穿格林尼治子午线时(也就是在格林尼治上空最高点时)的时间。自1924年2月5日开始,格林尼治天文台负责每隔一小时向全世界发放调时信息。由于地球每天的自转是有些不规则的,而且正在缓慢减速,因此格林尼治平时基于天文观测本身的缺陷,已经被原子钟报时的协调世界时(UTC)所取代。
CST (China Standard Time,中国标准时间) 是UTC+8时区的知名名称之一,比UTC(协调世界时)提前8个小时与UTC的时间偏差可写为+08:00.
http协议里respond的header日期
All HTTP date/time stamps MUST be represented in Greenwich Mean Time (GMT), without exception. 格林尼治标准时间。 在HTTP协议中,时间都是用格林尼治标准时间来表示的,而不是本地时间。 RFC 7231, section 7.1.1.2: Date
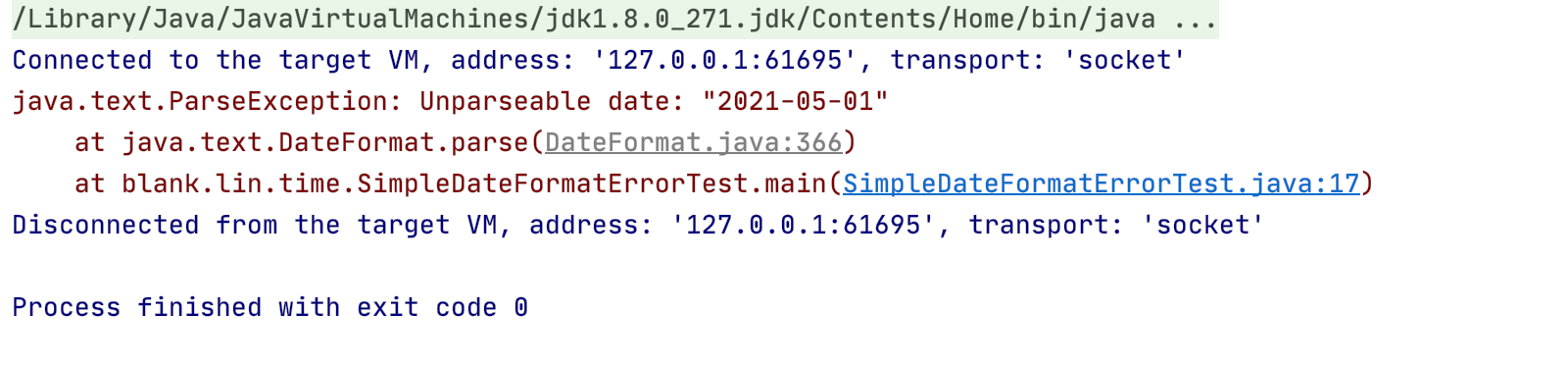
public class UTCTimeFormatTest { public static void main(String[] args) throws ParseException { //Z代表UTC统一时间:2017-11-27T03:16:03.944Z SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"); Date date = new Date(); System.out.println(date); String str = format.format(date); System.out.println(str); SimpleDateFormat dayformat = new SimpleDateFormat("yyyy-MM-dd"); String source ="2018-09-18"; //先将年月日的字符串日期格式化为date类型 Date day = dayformat.parse(source); //然后将date类型的日期转化为UTC格式的时间 String str2= format.format(day); System.out.println(str2); } }
private void initializeCalendar(Locale loc) { if (calendar == null) { assert loc != null; // The format object must be constructed using the symbols for this zone. // However, the calendar should use the current default TimeZone. // If this is not contained in the locale zone strings, then the zone // will be formatted using generic GMT+/-H:MM nomenclature. calendar = Calendar.getInstance(TimeZone.getDefault(), loc); } }
private static Calendar createCalendar(TimeZone zone, Locale aLocale) { CalendarProvider provider = LocaleProviderAdapter.getAdapter(CalendarProvider.class, aLocale) .getCalendarProvider(); if (provider != null) { try { return provider.getInstance(zone, aLocale); } catch (IllegalArgumentException iae) { // fall back to the default instantiation } }
Calendar cal = null;
if (aLocale.hasExtensions()) { String caltype = aLocale.getUnicodeLocaleType("ca"); if (caltype != null) { switch (caltype) { case "buddhist": cal = new BuddhistCalendar(zone, aLocale); break; case "japanese": cal = new JapaneseImperialCalendar(zone, aLocale); break; case "gregory": cal = new GregorianCalendar(zone, aLocale); break; } } } if (cal == null) { // If no known calendar type is explicitly specified, // perform the traditional way to create a Calendar: // create a BuddhistCalendar for th_TH locale, // a JapaneseImperialCalendar for ja_JP_JP locale, or // a GregorianCalendar for any other locales. // NOTE: The language, country and variant strings are interned. if (aLocale.getLanguage() == "th" && aLocale.getCountry() == "TH") { cal = new BuddhistCalendar(zone, aLocale); } else if (aLocale.getVariant() == "JP" && aLocale.getLanguage() == "ja" && aLocale.getCountry() == "JP") { cal = new JapaneseImperialCalendar(zone, aLocale); } else { cal = new GregorianCalendar(zone, aLocale); } } return cal; }
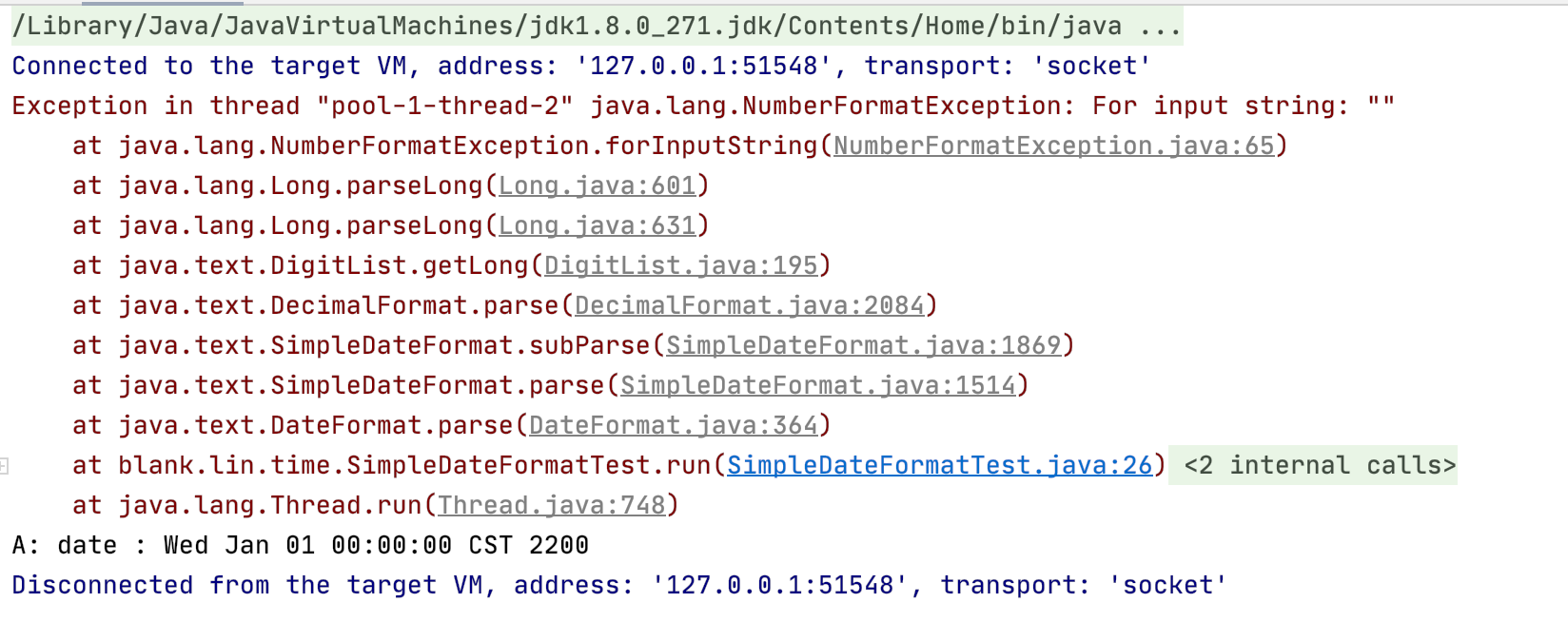
public class DateUtils { // 单例 private static Map<String, ThreadLocal<SimpleDateFormat>> localMap = new HashMap<>(); private static final Object lockObject = new Object();
public static SimpleDateFormat getSimpleDateFormat(String pattern) { ThreadLocal<SimpleDateFormat> threadLocal = localMap.get(pattern); if (threadLocal == null) { // 加锁,不重复初始化已经存在的pattern synchronized (lockObject) { // 再取一次是为了防止localMap被重复多次put已存在的pattern threadLocal = localMap.get(pattern); if (threadLocal == null) { System.out.println("put new sdf of pattern " + pattern + " to map"); threadLocal = new ThreadLocal<SimpleDateFormat>() { @Override protected SimpleDateFormat initialValue() { System.out.println("thread: " + Thread.currentThread() + " init pattern: " + pattern); return new SimpleDateFormat(pattern); } }; localMap.put(pattern, threadLocal); } } } return threadLocal.get(); }
/** * Set the value associated with key. * * @param key the thread local object * @param value the value to be set */ private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at // least as common to use set() to create new entries as // it is to replace existing ones, in which case, a fast // path would fail more often than not.
Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get();
tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }
ThreadLocal.createMap方法
1 2 3 4 5 6 7 8 9 10 11 12
/** * Create the map associated with a ThreadLocal. Overridden in * InheritableThreadLocal. * * @param t the current thread * @param firstValue value for the initial entry of the map */ void createMap(Thread t, T firstValue) { // 实例化一个新ThreadLocalMap对象 // this就是操作的ThreadLocal对象,firstValue就是要保存的值 t.threadLocals = new ThreadLocalMap(this, firstValue); }
case TAG_QUOTE_CHARS: while (count-- > 0) { if (start >= textLength || text.charAt(start) != compiledPattern[i++]) { pos.index = oldStart; pos.errorIndex = start; return null; } start++; } break; // 进入默认配置 default: // Peek the next pattern to determine if we need to // obey the number of pattern letters for // parsing. It's required when parsing contiguous // digit text (e.g., "20010704") with a pattern which // has no delimiters between fields, like "yyyyMMdd". boolean obeyCount = false;
// 在阿拉伯语中,负数的减号可以放在数字的后面(1111-) // In Arabic, a minus sign for a negative number is put after // the number. Even in another locale, a minus sign can be // put after a number using DateFormat.setNumberFormat(). // If both the minus sign and the field-delimiter are '-', // subParse() needs to determine whether a '-' after a number // in the given text is a delimiter or is a minus sign for the // preceding number. We give subParse() a clue based on the // information in compiledPattern. boolean useFollowingMinusSignAsDelimiter = false;
if (i < compiledPattern.length) { int nextTag = compiledPattern[i] >>> 8; if (!(nextTag == TAG_QUOTE_ASCII_CHAR || nextTag == TAG_QUOTE_CHARS)) { obeyCount = true; }
if (hasFollowingMinusSign && (nextTag == TAG_QUOTE_ASCII_CHAR || nextTag == TAG_QUOTE_CHARS)) { int c; if (nextTag == TAG_QUOTE_ASCII_CHAR) { c = compiledPattern[i] & 0xff; } else { c = compiledPattern[i+1]; }
// At this point the fields of Calendar have been set. Calendar // will fill in default values for missing fields when the time // is computed.
pos.index = start;
Date parsedDate; try { parsedDate = calb.establish(calendar).getTime(); // If the year value is ambiguous, // then the two-digit year == the default start year if (ambiguousYear[0]) { if (parsedDate.before(defaultCenturyStart)) { parsedDate = calb.addYear(100).establish(calendar).getTime(); } } } // An IllegalArgumentException will be thrown by Calendar.getTime() // if any fields are out of range, e.g., MONTH == 17. catch (IllegalArgumentException e) { pos.errorIndex = start; pos.index = oldStart; return null; }
public enum State { /** * Thread state for a thread which has not yet started. */ NEW,
/** * Thread state for a runnable thread. A thread in the runnable * state is executing in the Java virtual machine but it may * be waiting for other resources from the operating system * such as processor. */ RUNNABLE,
/** * Thread state for a thread blocked waiting for a monitor lock. * A thread in the blocked state is waiting for a monitor lock * to enter a synchronized block/method or * reenter a synchronized block/method after calling * {@link Object#wait() Object.wait}. */ BLOCKED,
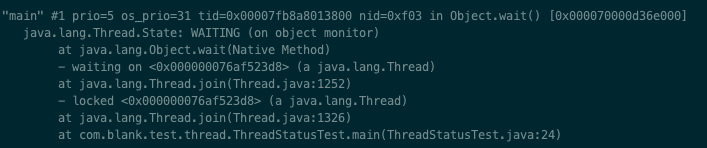
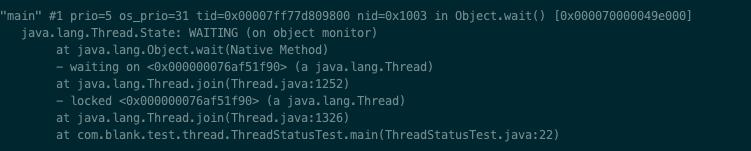
/** * Thread state for a waiting thread. * A thread is in the waiting state due to calling one of the * following methods: * <ul> * <li>{@link Object#wait() Object.wait} with no timeout</li> * <li>{@link #join() Thread.join} with no timeout</li> * <li>{@link LockSupport#park() LockSupport.park}</li> * </ul> * * <p>A thread in the waiting state is waiting for another thread to * perform a particular action. * * For example, a thread that has called <tt>Object.wait()</tt> * on an object is waiting for another thread to call * <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on * that object. A thread that has called <tt>Thread.join()</tt> * is waiting for a specified thread to terminate. */ WAITING,
/** * Thread state for a waiting thread with a specified waiting time. * A thread is in the timed waiting state due to calling one of * the following methods with a specified positive waiting time: * <ul> * <li>{@link #sleep Thread.sleep}</li> * <li>{@link Object#wait(long) Object.wait} with timeout</li> * <li>{@link #join(long) Thread.join} with timeout</li> * <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li> * <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li> * </ul> */ TIMED_WAITING,
/** * Thread state for a terminated thread. * The thread has completed execution. */ TERMINATED; }
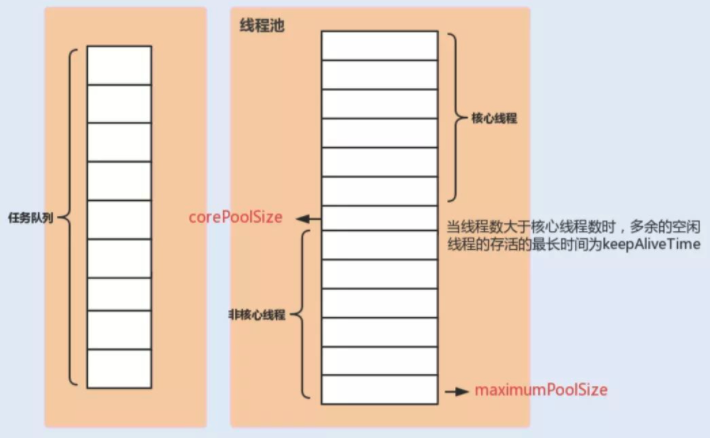
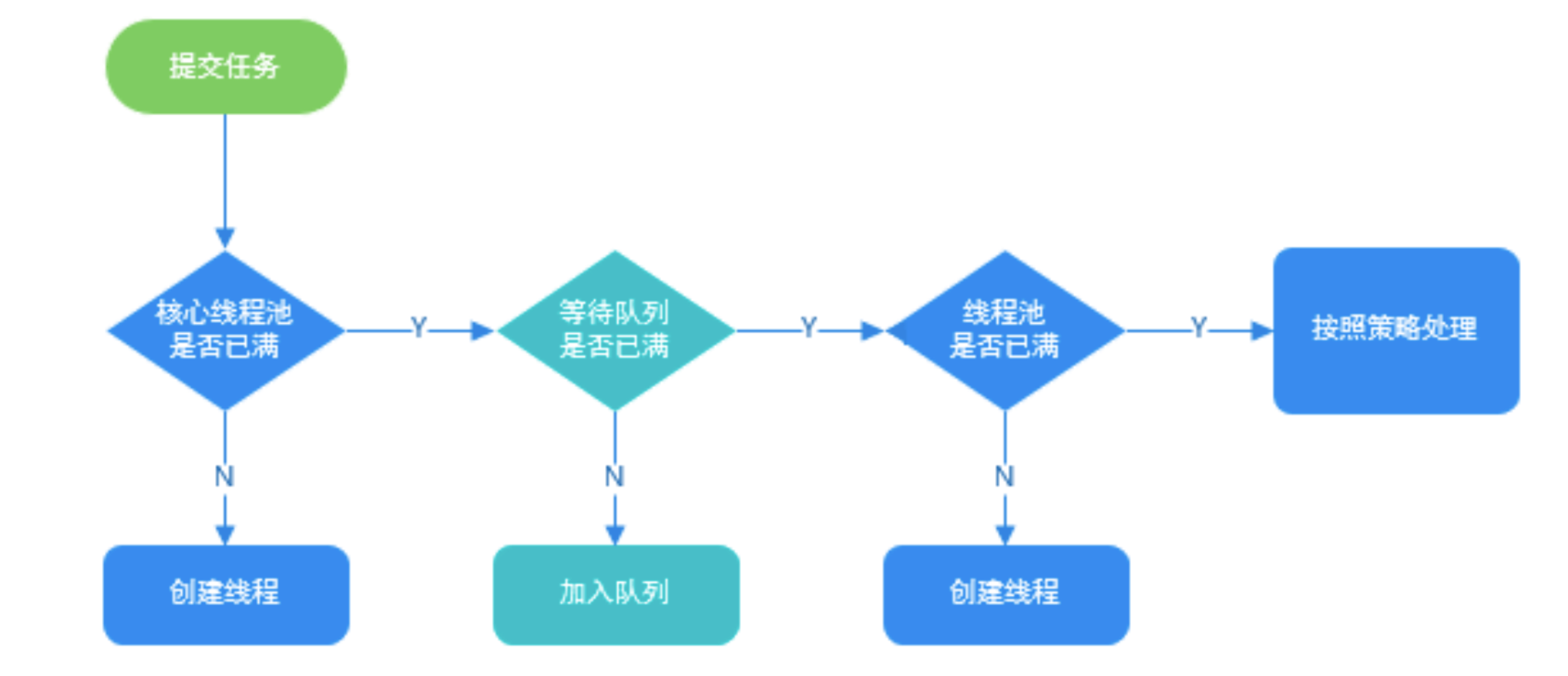
public class ThreadPoolTest { private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor( 1, 2, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(1) );
If fewer than corePoolSize threads are running, try to start a new thread with the given command as its first task. The call to addWorker atomically checks runState and workerCount, and so prevents false alarms that would add threads when it shouldn’t, by returning false.
If a task can be successfully queued, then we still need to double-check whether we should have added a thread (because existing ones died since last checking) or that the pool shut down since entry into this method. So we recheck state and if necessary roll back the enqueuing if stopped, or start a new thread if there are none.
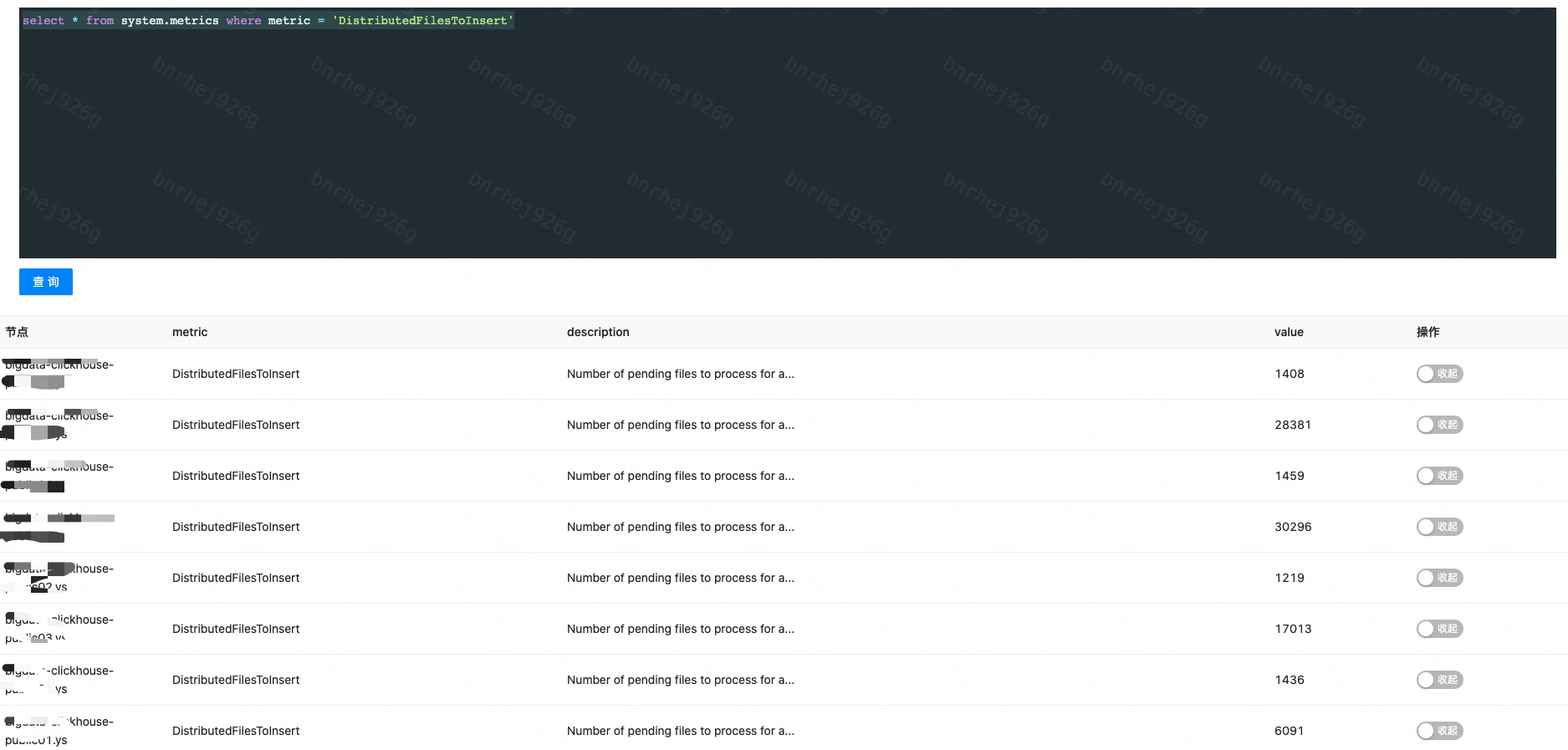





 ,每个 interval 都有多种资源(
,每个 interval 都有多种资源(